在配置BGP的时,通常最容易遇到的问题就是路由黑洞,那么什么是路由黑洞呢,简单的说,它会默默的将
数据包丢弃,使所有数据包有去无回。我们知道传统的IP路由查找,它是逐跳查找的,通俗一点就是当数
据包到达路由设备的时候,每一台设备都要查找路由表,并且在路由设备有路由的前提下才能转发报文。
对BGP来说由于存在iBGP水平分割规则,只把路由传递一跳,这是一种防环机制,所以在BGP的设计上有些
设备就不会运行BGP。
BGP是一种TCP的连接或者说是一种host-to-host的连接(可以跨越设备进行连接),所以路由传递是没有
问题的,但是数据包的路由却是有问题的。通常我们可以看到的现像是iBGP邻居关系可以正常建立,也就是
说控制平面看起来是正常的,但是数据平面确不可达。本篇我们就来介绍一下解决BGP路由黑洞的几种常见
的方法。
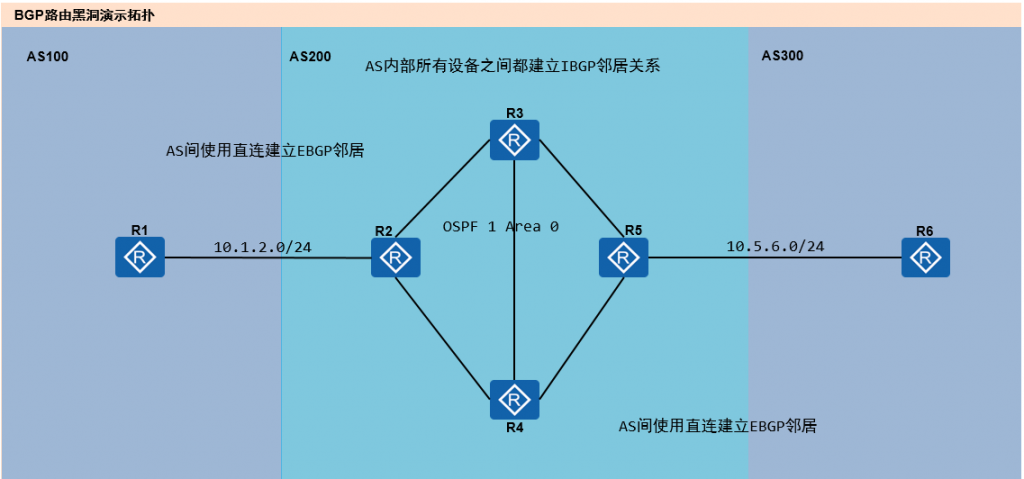
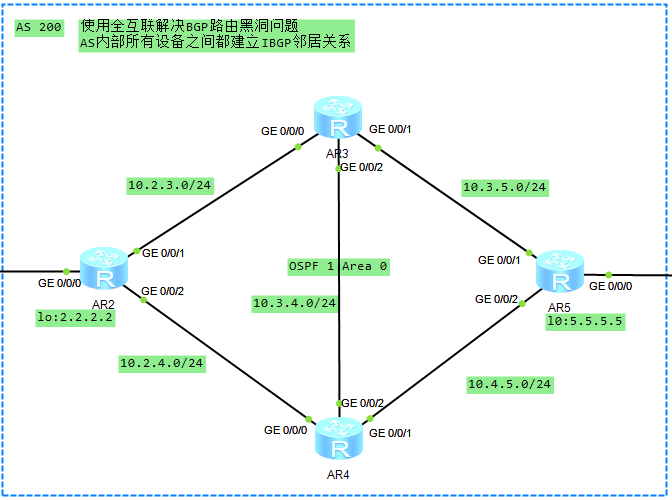
我们以下图中的拓扑为例来进行演示,配置要求如下:
1、在AS100和AS300中,路由器R1配置多个环回口,都发布到BGP内,并且做路由聚合。
2、在AS200中,AS内部所有设备之间建立iBGP邻居关系。
3、AS之间使用直连建立eBGP邻居关系。
4、配置完成后,要求R1与R6的环回口能够互通。
IP地址规划
R1:
lo0:1.1.1.1/24
lo1:192.168.1.1/24
lo2:192.168.2.1/24
lo3:192.168.3.1/24
R6:
lo0:6.6.6.6/24
lo1:172.17.1.6/24
lo2:172.17.2.6/24
lo3:172.17.3.6/24
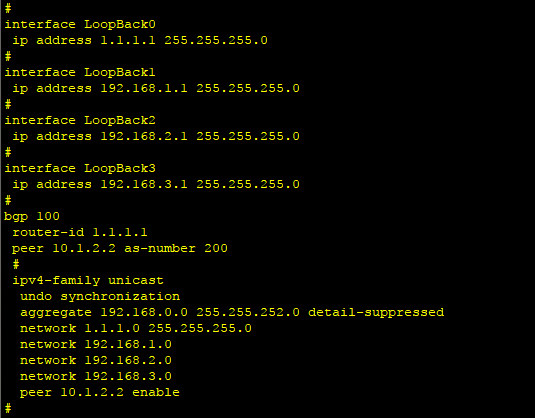
1、首先对各路由器进行基本的配置,以R1为例,配置各口的IP地址,配置环回口的IP地址,配置BGP 100,
并将环回口网段在BGP中进行宣告。以相同的方式配置AS300中的R6。
interface GigabitEthernet0/0/0
ip address 10.1.2.1 255.255.255.0
interface LoopBack0
ip address 1.1.1.1 255.255.255.0
interface LoopBack1
ip address 192.168.1.1 255.255.255.0
interface LoopBack2
ip address 192.168.2.1 255.255.255.0
interface LoopBack3
ip address 192.168.3.1 255.255.255.0
bgp 100
router-id 1.1.1.1
peer 10.1.2.2 as-number 200
ipv4-family unicast
undo synchronization
aggregate 192.168.0.0 255.255.252.0 detail-suppressed
network 1.1.1.0 255.255.255.0
network 192.168.1.0
network 192.168.2.0
network 192.168.3.0
peer 10.1.2.2 enable
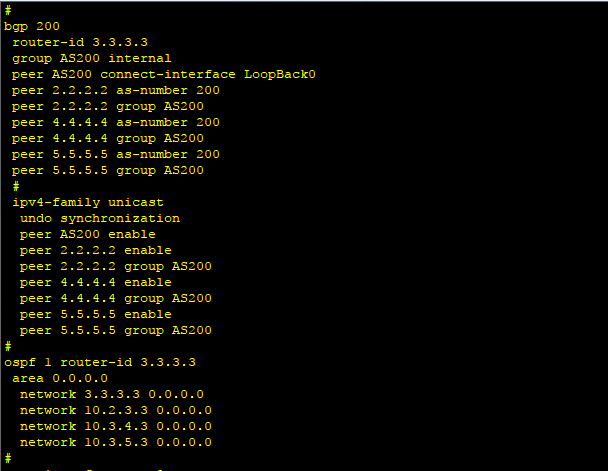
2、AS 200中的四台路上器,我们使用LoopBack 0接口建立iBGP邻居关系,同时在这四台路由器之间还要
配置IGP,这里我们使用OSPF协议。以R4的配置为例发下图,这里配置iBGP时可以使用AS Group以减轻配
置的工作量。
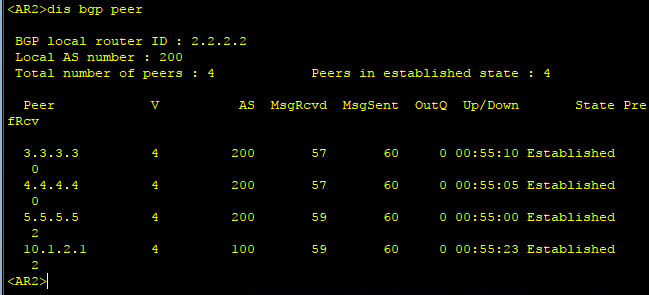
3、到这里所有配置完成后,查看BGP对等体,确认BGP邻居关系建立成功,从下图中可以看到R2分别与相应
路由器建立了eBGP和iBGP邻居关系。
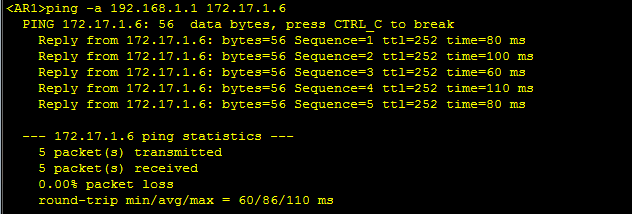
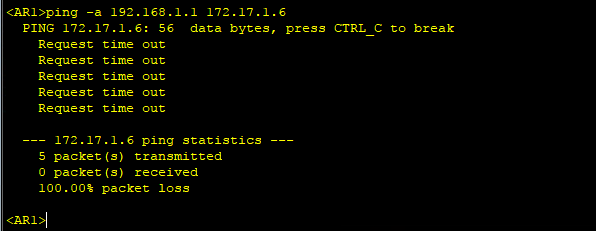
4、此时从R1环回口ping R6环回口,会发现根本Ping不通。这就是由于路由黑洞导致的。因为R3或者R4没
有这条路由条目,导致了R1把包发给R2,R2把包发给R3或R4,R3或R4查表发现没有这条路由条目,就把包
给丢弃,造成了路由黑洞。
5、解决路由黑洞的方法有以下几种:
1、在AS内使用物理线路的全互连,形成Full Mesh。
2、在AS内IBGP的对等体邻接关系的全互连,逻辑上形成Full Mesh。
3、将AS内部的边缘路由器上的BGP路由重新分发进IGP中。
4、在AS内部的边缘路由器之间建立Tunnel。
5、在AS内所有路由器上启用MPLS。
6、配置路由反射器RR。
7、联盟配置,现网中已经很少用到。
在AS内使用物理线路的全互连,形成Full Mesh
方法一、不需要演示,并且在现网中也基本不会用到,因为当路由器数量较多时,使用物理线路全互联是
不现实的,并且通常路由器之间可能还会有其它设备,比如交换机或者波分。所以我们主要来看一下后面
6种方法。
方法二、在AS内IBGP的对等体邻接关系的全互连,逻辑上形成Full Mesh
1、如下图可以看到,在AS200中,R2与R5属于OSPF中的ASBR,分别与R1和R6形成eBGP关系,它们在将EBGP
邻居发来的路由信息转发给R3和R4时,保留了EBGP传来的下一跳地址,但是对于R3与R4,它们并没有到达本
区域外的路由,这时我们就可以通过配置next-hop-local来解决这个问题。只需要在ASBR上进行修改,也
就是R2与R5。例如要将BGP的路由发送给3.3.3.3这个邻居时,将路由的下一跳设置成自己的地址,这个地址是
与3.3.3.3建立邻居所使用的源地址。缺省情况下,BGP设备向IBGP对等体发布路由时,不修改下一跳地址。
2、使用以下命令进行配置,以R2为例:
bgp 200
peer 3.3.3.3 next-hop-local
peer 4.4.4.4 next-hop-local
peer 5.5.5.5 next-hop-local
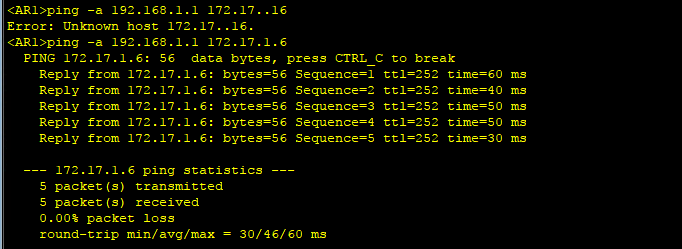
3、配置完成后,从R1环回口ping R6环回口,这时就可以Ping通了。
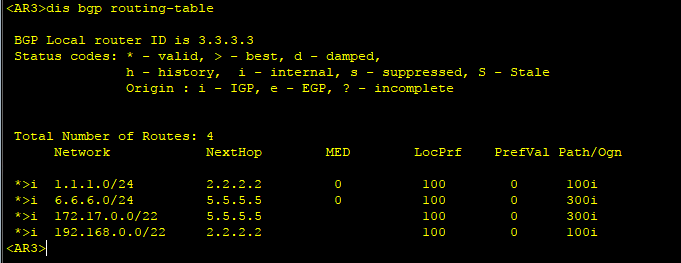
4、查看R3的BGP路由表,可以看到去往R1和R6的下一跳都指向了R2与R5。
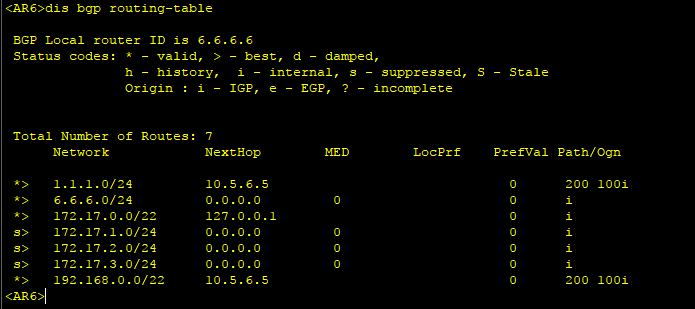
5、查看R6的路由表,可以看到环回口地址已经进行了路由聚合。
6、在方法二中,我们按要求配置完以后,来思考一下下面的三个问题,理解下面三个问题后,说明对BGP配
置有了更深的理解。
● 6.1、R3与R4是否有必要建立IBGP邻居关系?
Answer: 虽然配置中按要求在R3与R4之间建立了IBGP邻居关系,但它们之间并不需要建立IBGP邻居。因为
R3与R4都会收到R2与R5发布的EBGP路由,通过设置更新发送bgp报文的接口为loopback0接口后,路由就变
成了活跃路由。假设即使R2R4之间和R3R5之间的链路同时断掉,由于域内都配置了IGP,下一跳仍然可达。
● 6.2、R3与R4是否需要使用Nexthop local命令,如果使用有没有问题?
Answer: 不需要。因为只需要在ASBR上修改EBGP邻居发来的路由的Next_Hop。R3与R4不是ASBR。
如果在R3和R4上使用了该命令也没有影响,因为BGP向IBGP邻居发布引入的IGP路由时,缺省就将下一跳属性
改为自身的接口地址。
● 6.3、AS200内的数据转发路径是基于什么决定的?
Answer:其实这里并不涉及BGP路由选路,R5只收到一条路由,所以不触发选路。数据转发直接基于IGP最短
路径转发。
方法三、将AS内部的边缘路由器上的BGP路由重新分发进IGP中
1、在R3与R4上删除BGP 200
undo bgp 200
2、在R2和R5中把BGP重分发进到OSPF。
ospf 1
import-route bgp

3、配置完成后,从R1环回口ping R6环回口,可以Ping通。
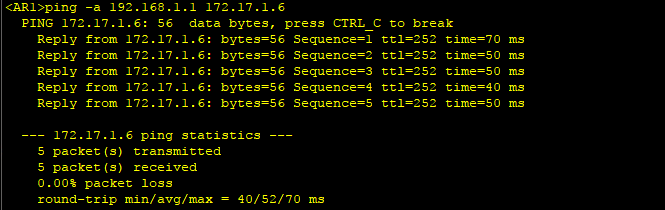
方法4、在AS内部的边缘路由器之间建立Tunnel
1、去掉R2和AR5的OSPF中重分发命令。
ospf 1
undo import-route bgp
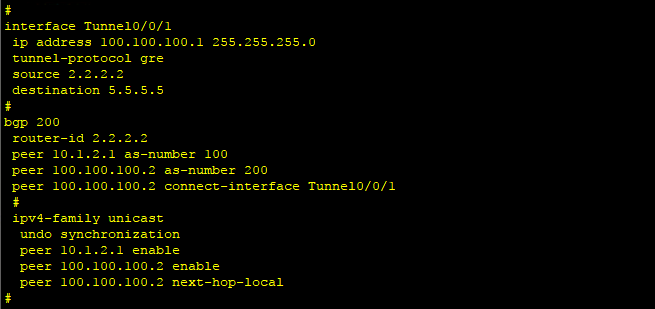
2、配置Tunnel口,以R2为例。
interface Tunnel0/0/1
ip address 100.100.100.1 255.255.255.0
tunnel-protocol gre
source 2.2.2.2
destination 5.5.5.5
3、修改BGP配置使用Tunnel IP建立Peer,以R5为例。
bgp 1
undo peer 2.2.2.2
peer 100.100.100.1 as-number 200
peer 100.100.100.1 next-hop-local
peer 100.100.100.1 connect-interface Tunnel 0/0/1
4、 配置完成后,从R1环回口ping R6环回口,可以Ping通。
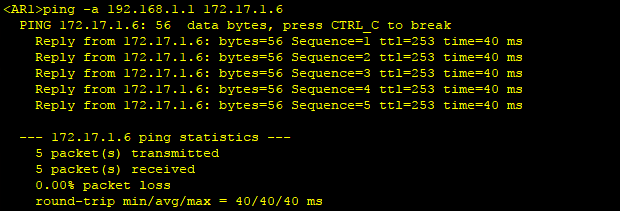
方法5、 在AS内所有路由器上启用MPLS
1、首先删除R2和R5的Tunnel口设置。
undo int tunnel 0/0/1
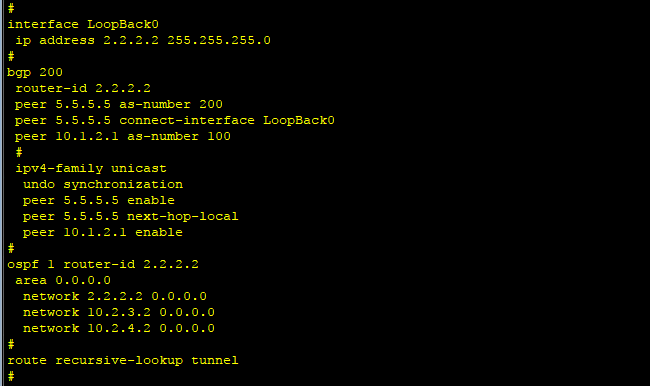
2、R2与R5修改BGP200的peer,还是使用loopback 0地址建立peer。以R2为例。
bgp 200
undo peer 100.100.100.2
peer 5.5.5.5 as-number 200
peer 5.5.5.5 connect-interface LoopBack0
peer 5.5.5.5 next-hop-local
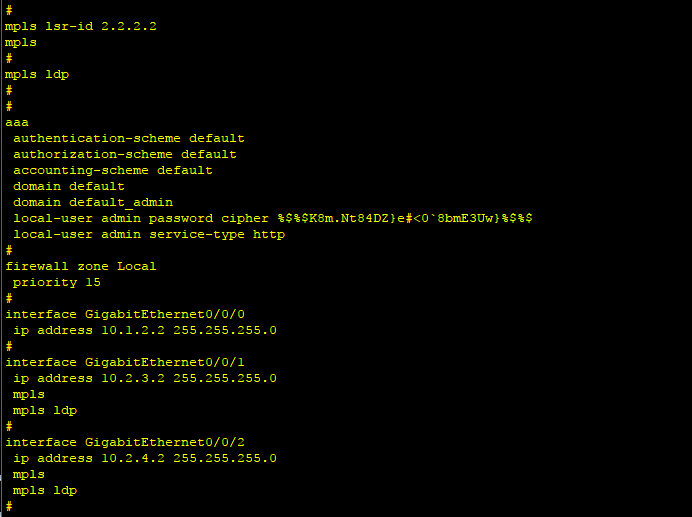
3、在4台路由器都配置MPLS,以R2为例。
mpls lsr-id 2.2.2.2
mpls
mpls ldp
int g0/0/1
mpls
mpls ldp
int g0/0/1
mpls
mpls ldp
route recursive-lookup tunnel
4、配置完成后,从R1环回口ping R6环回口,可以Ping通。
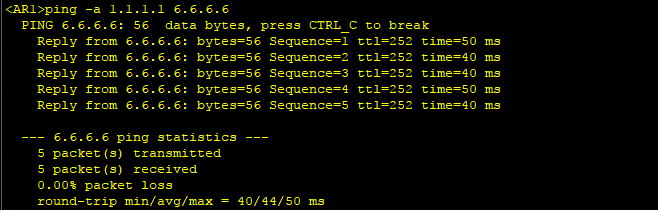
方法6、配置路由反射器RR
1、我们还可以使用路由反射来描述一个BGP Speaker通告一条IBGP路由到另外一个IBGP对等体。而这样
一个BGP Speaker通常被称为路由反射器(Route Reflector, RR),这样的一条IBGP路由被称为反射路由。
2、路由反射宣告原则:从非客户机IBGP对等体学到的路由,发布给此RR的所有客户机,不会反射给所有的
非反射客户端。从客户机学到的路由,发布给此RR的所有非客户机和客户机(发起此路由的客户机除外)。
从EBGP对等体学到的路由,发布给所有的非客户机和客户机。
● Client只需维护与RR之间的IBGP会话
● RR与RR之间需要建立IBGP的全互连
● Non-Client与Non-Client之间需要建立IBGP全互
● RR与Non-Client之间需要建立IBGP全互连
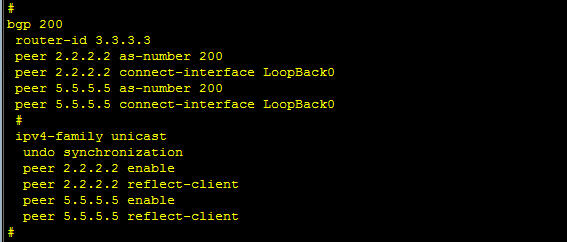
3、配置RR非常简单,只需要在BGP peer中加入一条配置如下,将其配置为RR客户机即可,在我们的拓扑中
,这时R2与R5就不需要建立iBGP邻居关系了,这时需要同时在R3与R4上配置RR。注意配置RR就不再需要再配
置next-hop-local。以R3为例。
bgp 200
peer 2.2.2.2 reflect-client
peer 5.5.5.5 reflect-client
4、配置完成后,从R1环回口ping R6环回口,可以Ping通。