上一篇文章我们介绍了DSF的基本组件,包括Storage Pool、Storage Container、Volume Group等
组件以及创建方法。在本篇我们来介绍一下DSF的其它功能,包括oplog、Deduplication、Compres
sion以及Erasure coding。
OpLog (持久写缓冲)
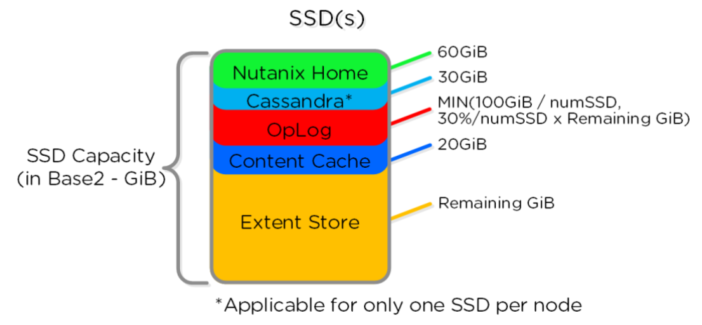
1、oplog是位物存储层上的写缓存。当VM通过Hypervisor提交写请求时,该请求被发送到主机上的
CVM。为了对客户机VM提供快速响应,首先将这些数据存储在元数据驱动器上,存储在称为oplog的
存储子集中。Oplog数据定期传输到集群中的持久存储中。为了提高性能,数据在本地编写,并在多
个节点上复制,以获得高可用性。OpLog 分布在所有 SSD 设备里。
2、Oplog 类似于文件系统的日志(journal),用来处理突发的写操作,并聚合这些写操作顺序地
写到Extent Store中。为了保证数据高可用性的要求,在写操作完成(Ack)之前,数据写入Oplog
的同时被同步复制到另一个CVM的Oplog中。所有CVM的Oplog 都参与复制操作,并依据CVM 负载情况
自动选择。 Oplog保存在CVM的SSD层以提供极高的IO写性能,特别是随机IO写操作。对于顺序的IO
写操作会直接写到Extent Store上而绕过Oplog。如果数据当前在Oplog中,所有的读请求会直接从
Oplog中反馈,直到数据被合并推送到Extent Store中后,只有当读的数据不在Oplog中,读请求才会
从Extent Store/Unified Cache中获得。如果在容器中的指纹(消重功能) 被启用时,则所有写IO
操作时,数据块会被标记指纹,以便在数据进入Unified Cache时进行消重操作。
3、vDisk的Oplog计算:Oplog是共享资源,但分配是在vDisk基础上完成确保每个vDisk有均等机会。
这由每个vDisk Oplog限制(Oplog 中每个vDisk的最大数据量)实现。带有多个vDisk(s)的虚拟机可
以使用每个vDisk限制乘以磁盘数量的Oplog。每个vDisk Oplog的限制当前是6GB(4.6 开始),以前
版本最大2GB。由下面的Gflag控制: vdisk_distributed_oplog_max_dirty_MB。
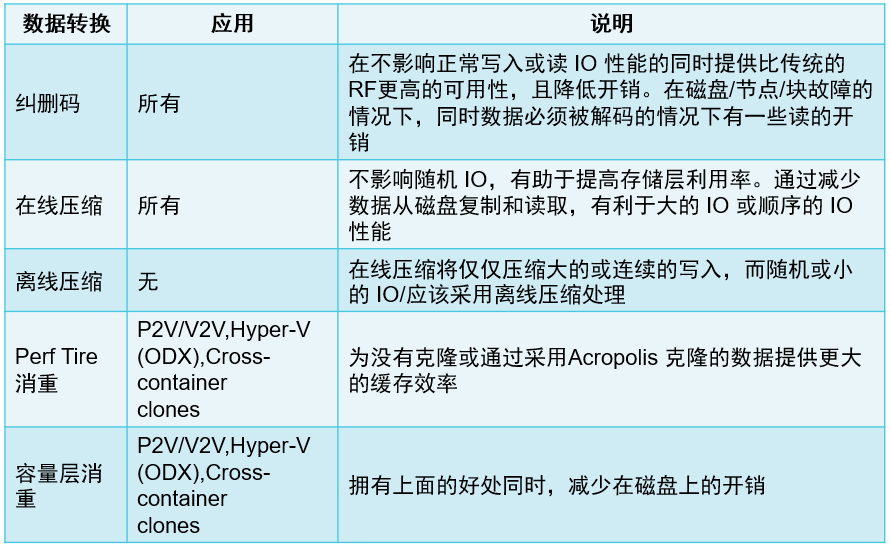
容量优化
Nutanix平台集成了多种存储优化技术并协同工作,使任何工作负载的可用容量被有效利用,这些技术
具备智能和自适应的工作特性,消除了需要手动配置和微调。这些容量优化技术主要包括:
● 数据压缩(Compression)
● 重复数据删除(Deduplication)
● 纠删码(Erasure Coding)
数据压缩(Compression)
1、存储容器可以启用压缩。压缩优化了集群中存储的使用。启用压缩还有其他好处,比如通过减少
I/O和提高内存效率来优化I/O带宽利用率,这可能对整体系统性能有积极的影响。注意:如果元数据
使用率高,则自动禁用压缩。如果自动禁用压缩,将生成警报。建议总是使用在线压缩(压缩延迟=
0),因为它只压缩较大的/顺序的写入,不影响随机写入性能。这还增加了SSD层的可用大小,提高
了有效性能,并使更多的数据位于SSD层中。
2、对于以在线方式写入和压缩的较大数据或顺序数据,RF复制将发送压缩数据,这进一步提高了性
能,因为它跨线发送的数据较少。在线压缩也与纠删码完美匹配。例如,通过使用字典在0和1之间进
行转换,算法可以用较小的0和1字符串表示一组位,或者公式可以插入引用或指向程序已经看到的0
和1字符串的指针。文本压缩可以简单到删除所有不需要的字符,插入一个重复字符来指示一个重复
字符串,并用一个较小的位串替换一个经常出现的位串。数据压缩可以将文本文件减少到原始大小的
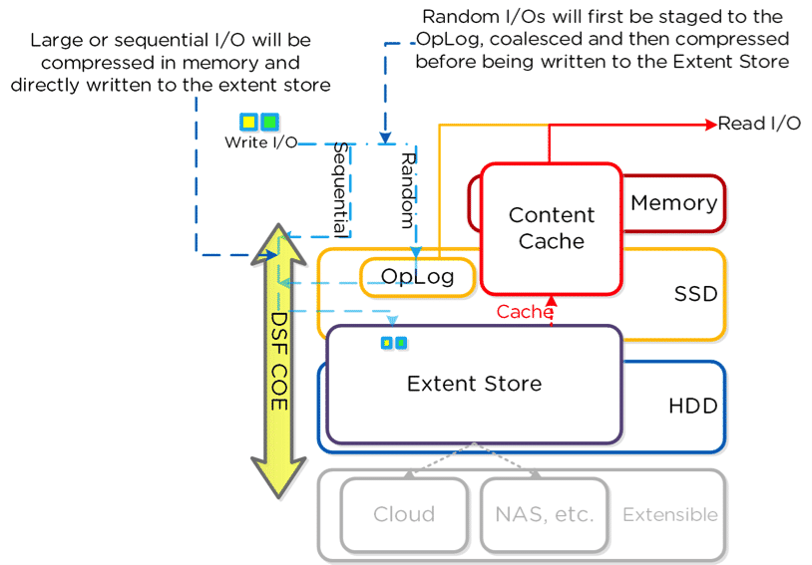
50%或更高的百分比。当写数据到Extent Store(SSD+HDD)时,在线压缩会压缩顺序数据流或者大
I/O(大于64K)。包含从Oplog落下来的数据和不使用Oplog的顺序数据。
3、离线压缩开始按照正常方式写数据(以不压缩状态),然后借助Curator框架在集群范围压缩数
据。当在线压缩开启但是I/O都是随机数据,数据会以未压缩的状态写入Oplog,归并,然后在内存中
压缩后写入Extent Store。Nutanix借助LZ4和LZ4HC进行数据压缩(Asterix 版本及以后)。在Aste
rix版本之前,使用的是Google Snappy压缩库,可以提供良好的压缩率,最小的计算开销和极快的压
缩解压缩速度。一般数据被使用 LZ4压缩,LZ4在压缩率和性能之间ᨀ供非常好的平衡。对于冷数据,
LZ4HC可以提供更好的压缩率。
4、以下两个类型被归类为冷数据:
● 正常数据:三天没有读写访问
(Gflag:curator_medium_compress_mutable_data_delay_secs)
● 不可更改数据(快照):一天没有访问(Gflag:
curator_medium_compress_immutable_data_delay_secs)
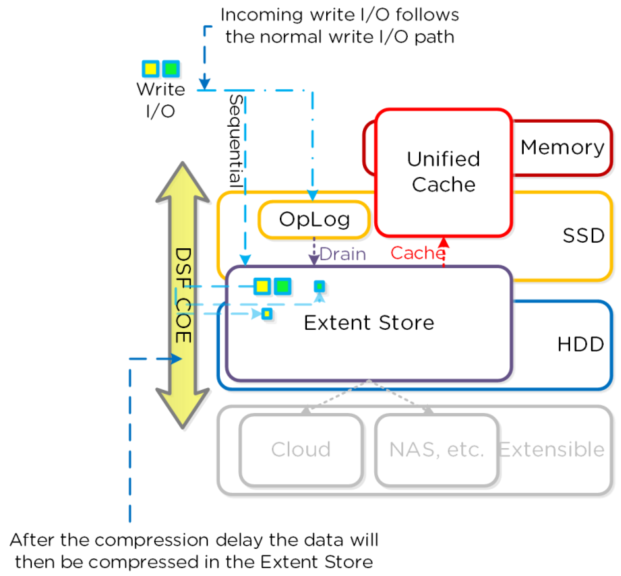
5、对于离线压缩,所有新的写I/O按照正常DSF的I/O通道没有压缩地写入。当压缩延迟(可配置)到
达后,数据才有资格被压缩。压缩可以发生于Extent Store的任何地方。 离线压缩使用Curator的
MapReduce框架,所有节点将参与压缩任务。压缩任务将被Chronos控制。对于读 I/O, 数据首先在
内存解压缩之后 I/O 被读取。
重复数据删除(Deduplication)
1、重复数据删除类似于增量备份,是一种消除冗余数据并减少存储开销的过程。重复数据消除允
许在Nutanix存储层上共享Guest虚拟机数据。可以在存储容器上仅启用缓存重复数据消除(Cache
Deduplication),也可以同时启用缓存和容量重复数据消除(Capacity Deduplication)。
● 缓存重复数据消除
启用读缓存的缓存重复数据消除以优化性能。默认情况下不会启用缓存重复数据消除,需要Start
er或更高版本的许可证,则可以使用缓存重复数据消除。
● 容量重复数据消除
启用持久性数据的容量重复数据消除以减少存储使用。默认情况下不会启用容量重复数据消除,需
要Pro或更高版本的许可证,则可以使用容量重复数据消除。请注意,只有启用了缓存重复数据消除,
才能启用容量重复数据消除。
2、重复数据消除在存储容器级别启用(缓存重复数据消除的缓存属性和容量重复数据消除的容量属
性)。这些存储容器属性可以在Web控制台或NCLI中设置。此外,启用重复数据消除的集群中的控制
器虚拟机需要配置额外的RAM:
• Cache deduplication: 24 GB RAM
• Capacity deduplication: 32 GB RAM
3、弹性消重引擎是DSF中一个基于软件的特性,它允许在容量层面(HDD)和性能层面(SSD/内存)
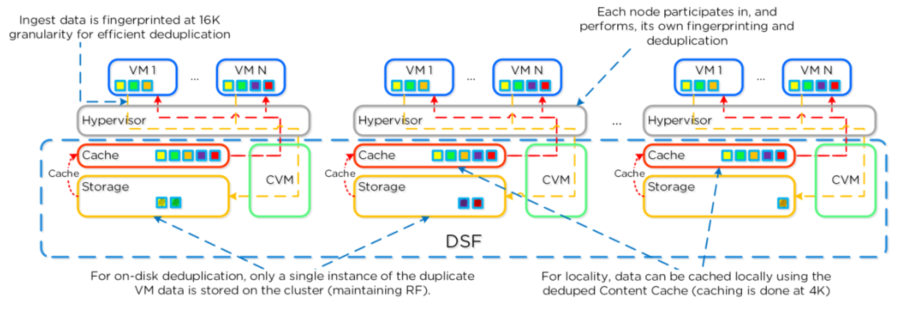
对数据进行消重操作。顺序的数据流在写入(ingest)时,按照16KB粒度进行SHA-1的散(hash)运
算标记指纹。指纹标记操作仅在数据块被写入(ingest)的时候进行,并作为该数据块的元数据信息
的一部分被持久保存。注意:最初采用4KB粒度进行指纹标记,然而经过测试,16KB粒度的指纹标记
操作能在消重能力和减少元数据(metadata)开销之间取得最好的平衡。当已消重数据进入unified
cache之后,将以4KB粒度进行消重。传统消重操作需要在后台进行数据块扫描,数据被重新读取并开
销大量系统资源,Nutanix在写入时执行在线的指纹标记操作。消重时,外部存储上重复数据块可以
被直接删除,而无需重新读取和计算指纹。为了使元数据更加高效率,指纹标记参考计数被监控来跟
踪可消重能力。参考计数低的指纹计数将被丢弃以减少元数据的过载。为最小化碎片,完全extents
是用于在容量层面的消重首选.
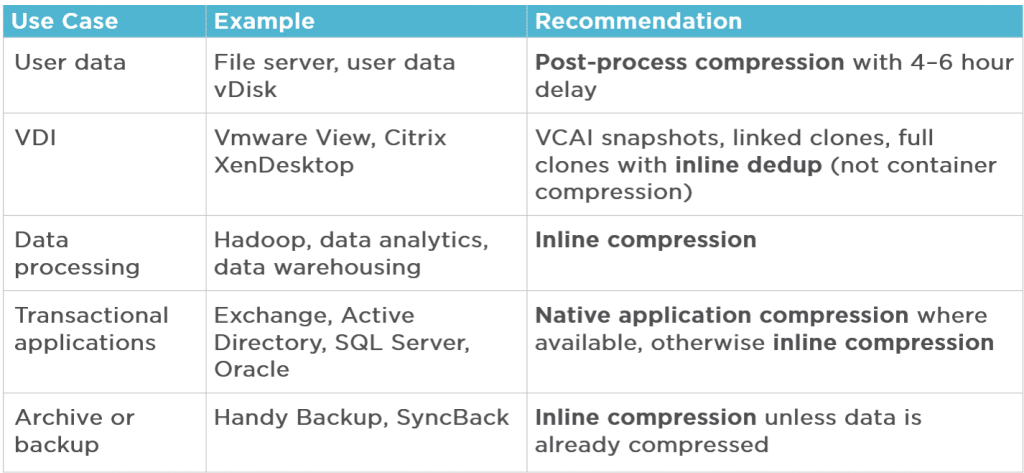
4、下图为是否使用重复数据消除功能的建议场景。

5、为了提高元数据开销的效率,监控指纹引用计数以跟踪可重复数据消除性。将丢弃具有低引用计
数的指纹,以最小化元数据开销。为了最大限度地减少碎片,容量层重复数据消除首选全数据块。
● 重复数据消除允许在Nutanix存储层上共享Guest VM数据。
● 当活动数据不再适合于性能层时,Guest VM的性能会受到影响。
6、当在适当的情况下使用时,重复数据消除会使性能层的有效大小变大,从而能够容纳更多活动数
据。块级重复数据消除在文件中查找并保存每个块的唯一迭代。所有的块(blocks)都被分成小块
(Chunks)。每个数据块都使用sha-1哈希算法进行处理。这个过程为每个piece生成一个唯一的数字
:散列数。当一个数据块接收到一个散列数时,该数字将与其他现有散列数的索引进行比较。如果散
列号已经在索引中,则该数据段被视为重复数据,不需要再次存储。否则,新的散列号将添加到索引
中并存储新数据。如果更新文件,则仅保存更改的数据,即使文档或演示文稿只有几个字节发生了更
改。这些更改并不构成一个全新的文件。这种行为使块重复数据消除(与文件重复数据消除相比)更
加高效。但是,块重复数据消除需要更多的处理能力,并使用更大的索引来跟踪单个块。
7、线内重复数据消除(Inline deduplication)对于具有大型通用工作集的应用程序非常有用。
● 删除性能层中的冗余数据
● 允许更多活动数据,可以提高虚拟机的性能
● 利用硬件辅助功能;软件驱动
8、后处理重复数据消除(Post-process dedup)对于具有完整克隆的虚拟桌面(VDI)非常有用。
● 减少容量层中的冗余数据,提高群集的有效存储容量
● 分布在集群中的所有节点上(全局)
纠删码(Erasure Coding)
1、Nutanix平台依赖于RF来保护数据和可用性,这个方法提供了最高程度的可用性,因为当数据失
效时,不需要从其他存储位置或者重新计算来读取。然而,由于需要完全复制,存储资源的成本比
较高。为了提供一个可用性和降低存储容量的平衡, DSF提供了使用纠删码(EC)来对数据进行编
码。
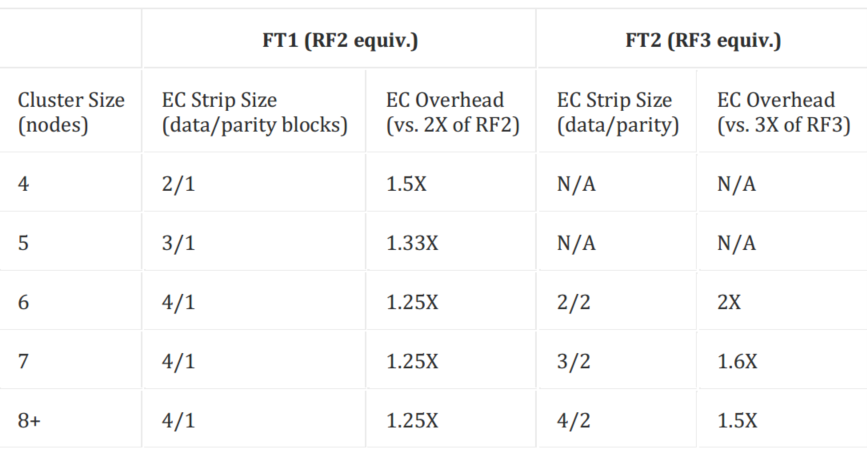
2、和RAID 4,5,6等级别的概念相似,校验位是计算出来的。EC对不同节点上的数据块条带进行编
码和计算校验位。当主机或者磁盘故障时,校验位可以被利用为计算任何缺失的数据块(解码)。在
DSF里,数据块是一个extend组,每个数据块必须在不同的节点上,属于不同的vDisk。一个条带里的
数据块的数量和校验块是可以基于要求能容忍的失效而配置的。配置通常采用数据块数量/校验块数量
来表示。例如,RF2级别的可用性(N+1)在一个条带里能够包括3个或者4个数据块和一个校验数据块
(例如3/1或者4/1)。RF3级别的可用性(N+2)在一个条带里能够包括3个或者4个数据块和两个校验
数据块(例如3/2或者4/2)。预期的消耗可以用校验块数量/数据块数量来计算。例如,一个4/1 的条
带有25%的消耗,或者是1.25(RF2是2)。一个4/2条带有50%的消耗或者是 1.5(RF3是3)。下图列出
了常见条带大小和消耗的例子:
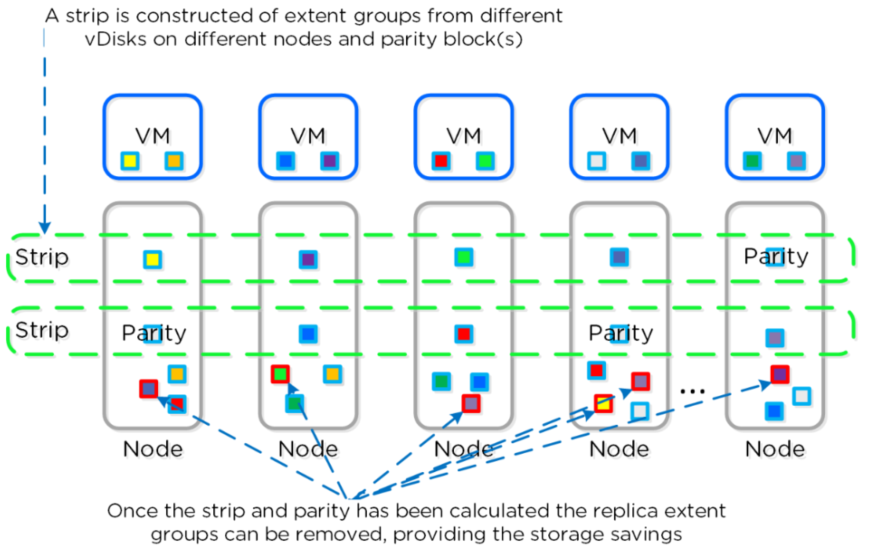
3、典型的DSF RF的环境如下图,在这个场景里,我们有混合RF2和RF3数据的集群,主数据块在本地,
副本数据块在集群的其它节点上。当Curator运行完全扫描时,它会发现合适的extend组可以被编码
的。合适的extend组必须是“写冷的”,也就是它们写入超过一个小时以上。在合适的extend组被发现
后,编码的任务将通过Chronos分发和控制。
4、一旦数据被成功地编码(条带和校验计算后), extend组的副本将被删除。如下图为运行CE节省
存储空间后的环境。纠删码和在线压缩可以完美地结合使用, 大大节省存储空间。
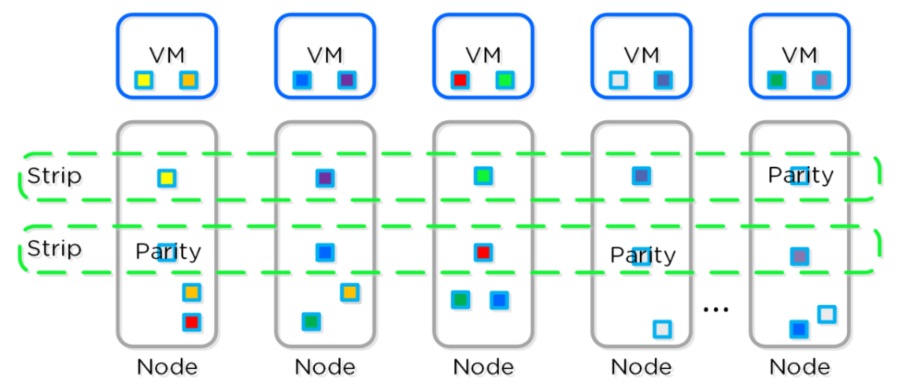
5、Nutanix维护数据副本以实现数据弹性。如果配置了冗余系数2,则会保留两个数据副本。例如,
考虑一个具有4个数据块(A B C D)的6节点集群,如下图所示。如果配置了冗余系数2,则会保留
两份数据副本。在下图中,绿色文本表示数据副本。

6、一旦数据变冷,纠删码引擎通过获取所有数据副本并执行独占或操作,为数据副本计算奇偶校
验“P”。

7、通过奇偶校验实现冗余会导致数据减少,因为系统上的总数据现在是A+B+C+D+P而不是2×
(A+B+C+D)。注:奇偶校验“P”和数据块A B C D放置在不同的节点上,以在冗余系数2配置中实现
单节点故障保护。

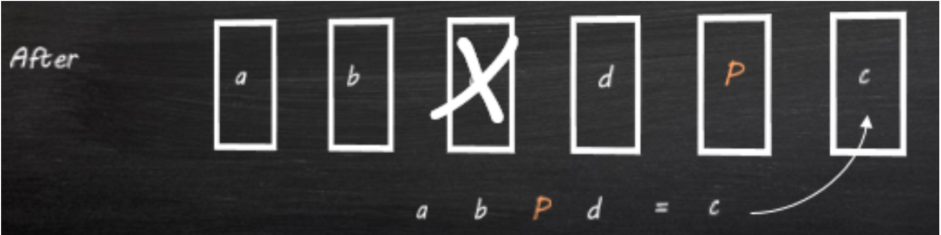
8、如果包含数据块C的节点出现故障,则使用下图中显示的纠删码条带(A B D和P)的其余部分来恢
复块C。使用条带的其他成员(A、B、D和P)重建数据块C。然后将块C放置在一个节点上,该节点没有
此纠删码条带的任何其他成员。注意:在冗余因子3配置中,保持两个奇偶校验块,其中两个节点可以
同时失败而不丢失数据。利用两个奇偶校验块,当两个节点同时发生故障时,系统可以重建丢失的数
据。
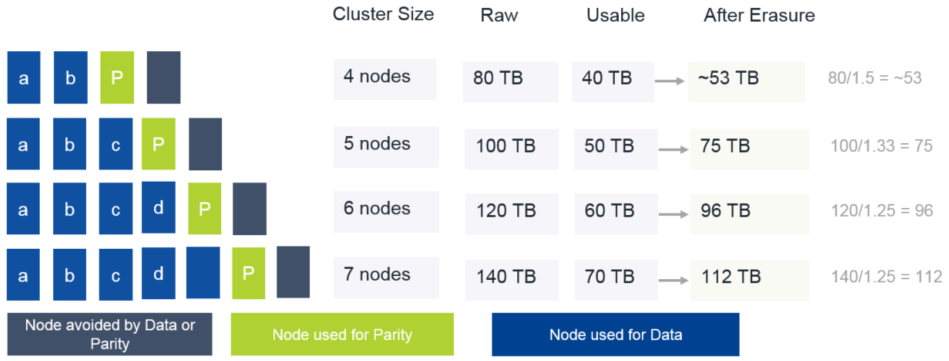
9、纠删码功能的节省取决于数据的集群大小和冷度。考虑一个配置了冗余系数2的6节点集群。条带大
小可以为5:4个节点用于数据,1个节点用于奇偶校验。包含纠删码条带的数据和奇偶校验将在集群中
留下一个节点,以确保如果发生节点故障,则可以重建节点。如果使用条带(4,1),则开销为25%
(1表示奇偶校验,4表示数据)。没有纠删码,开销是100%。考虑一个集群,它为每个节点提供20TB
的原始空间。下图显示了启用纠删码后可能发生的群集大小、可能的条带和近似节省的各种配置。
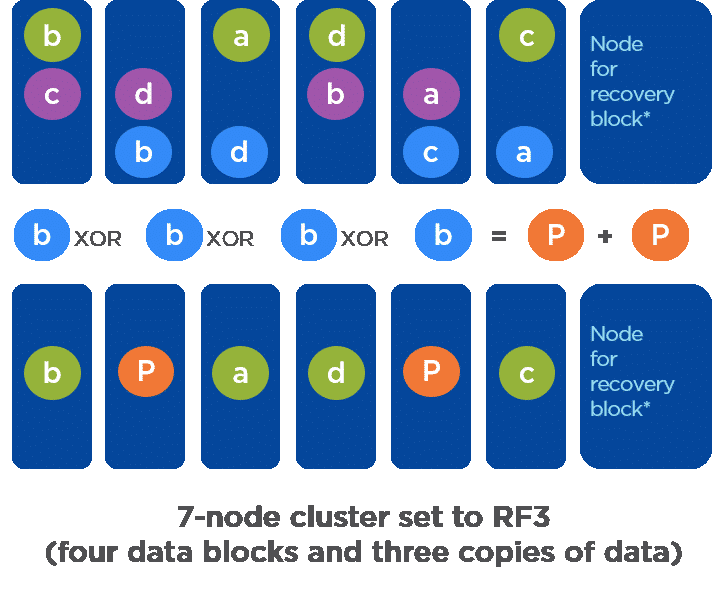
10、一旦数据变冷,擦除代码引擎通过获取所有数据副本(“d”)并执行独占或操作来创建一个或多
个奇偶校验块,为数据副本计算双奇偶校验(2x“p”)。两个奇偶校验块就位后,第二个和第三个副
本将被删除。最终得到12个(原来的三个副本)+2个(奇偶校验)-8个(删除第二个+第三个副本)
=6个块,这节省了50%的存储空间。
11、使用纠删码的一些条件:
● 集群至少需要4个节点
● 不要在具有多次重写的数据集上使用纠删码
● 最适合快照、文件服务器存档、备份和其他“冷”数据
● 在故障场景中,读取性能可能会下降
12、下图为在Prism Web控制台中查看总体容量优化。
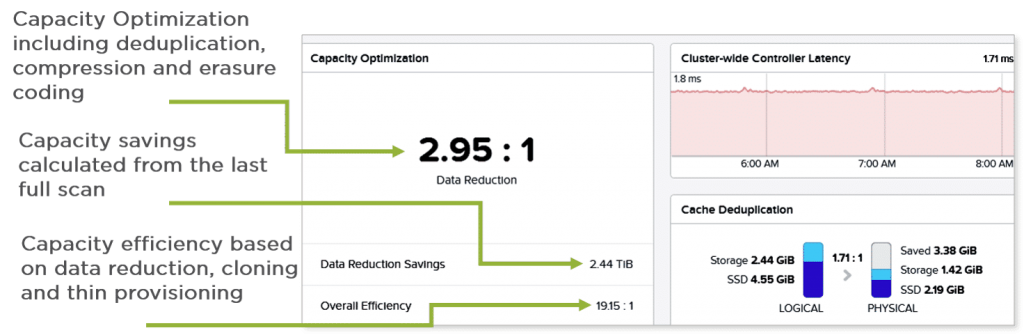
13、优化类型与高级工作负载对应关系