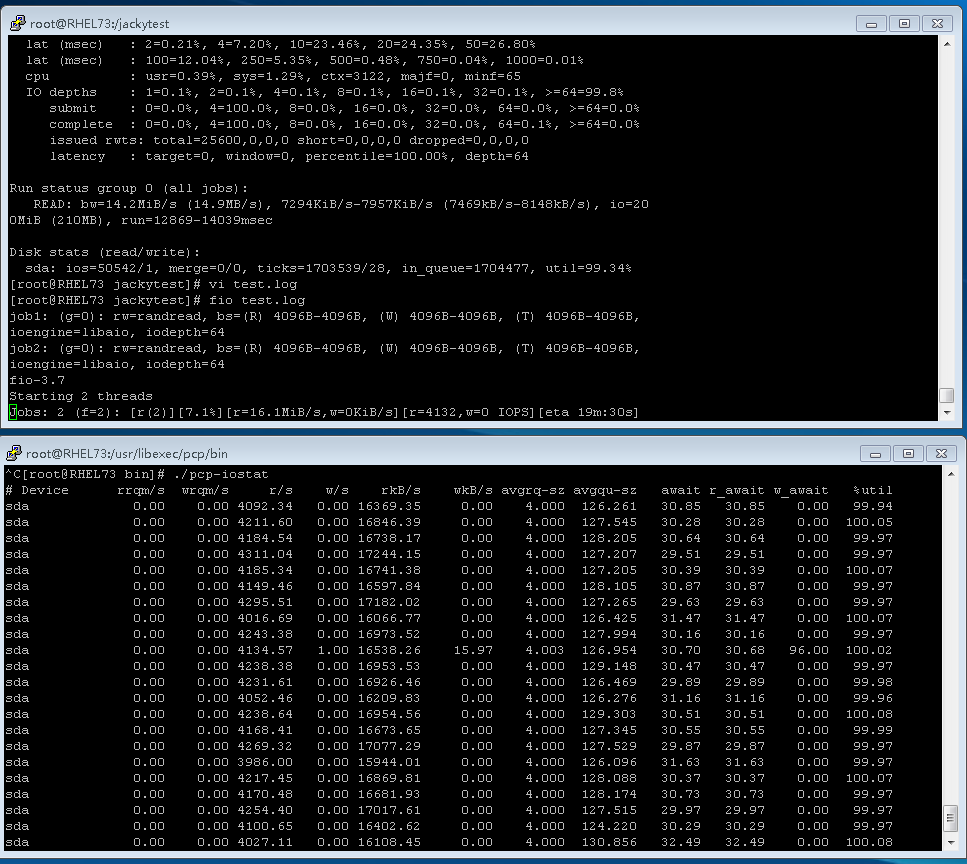
FIO - flexible I/O tester,是一种用来产生大量执行用户指定的特定类型的I/O操作的线程或进程的
工具。FIO的典型用法是编写与要模拟的I/O负载匹配的作业文件并根据作业文件进行测试。
随着块设备的发展,特别是SSD现在的普及度越来越高,设备的并行度也越来越高。设备的io depth也在
不断的提高。 在对硬盘进行性能测试时,也更多的使用异步的方式,FIO是一个非常灵活的io测试工具,
可以通过多线程或进程模拟各种io操作,FIO也是在售前技术支持中经常用到的性能测试分析工具。对于售
后技术支持,FIO也非常适合用来做磁盘压力测试,模拟用户的磁盘IO压力。
安装FIO:
1,测试是在一台RHEL7.3的虚拟机中进行
2,下载FIO,可从github中下载最新版本
https://github.com/axboe/fio
3,将FIO拷贝到Linux系统中相应的目录,可以使用WinSCP
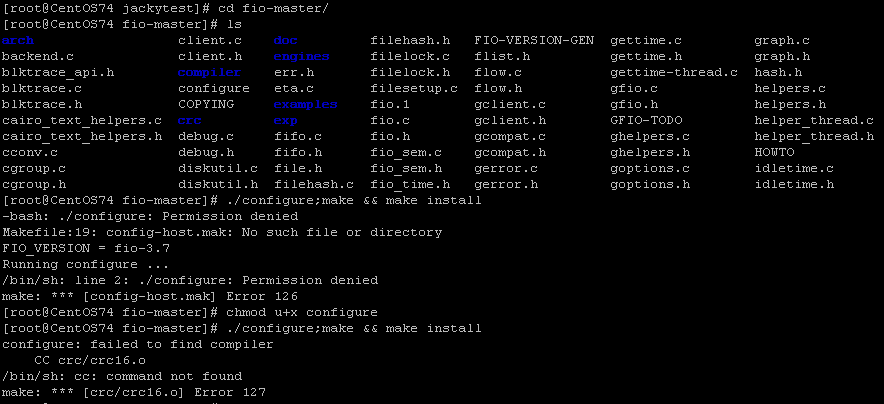
4,在github上面下载的是源代码,需要在系统中编译安装,可使用命令“./configure;make && make
install”,第一次执行编译时,提示没有权限,可使用chmod 命令更改权限,再次执行编译提示找不到
编译器,如下图:
5,这时我们需要在系统中先安装编译器,Install GCC (C and C++ Compiler) and Development
Tools。 安装前检查YUM源,如果系统不可以访问互联网,需要先配置本地YUM源
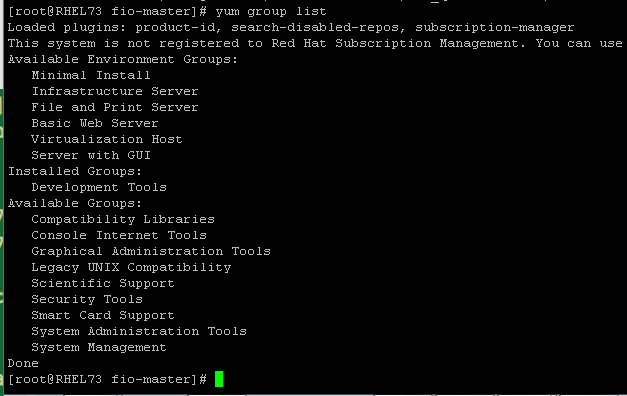
6,确认YUM源可用,然后使用命令yum group list,查看Development Tools是否已经安装,如果未
安装需要安装上
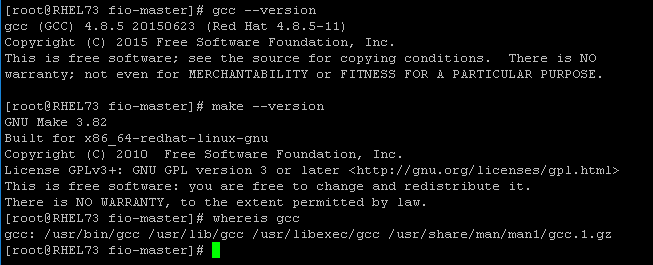
7,使用yum group install “Development Tools”命令进行安装。安装完成后,检查GCC版本确认
GCC已经安装成功。
8,回到FIO目录,再次编译安装FIO,使用命令“./configure;make && make install”,等待其安装
完成。
9,安装完成后,就可以执行fio测试了,例如执行如下命令:
fio -rw=randwrite -ioengine=libaio -direct=1 -thread -numjobs=1 -iodepth=64 -filename=/testfolder/fio.test -size=100M -name=job1 -offset=0MB -bs=4k -name=job2 -offset=10G -bs=512 -output TestResult.log
10,如果报错提示: fio: engine libaio not loaded, 说明没有加载libaio-devel, 使用命令
“yum install -y libaio-devel” 进行安装。
11,再次执行命令:fio -rw=randwrite -ioengine=libaio -direct=1 -thread -numjobs=1 -iodepth=64 -filename=/testfolder/fio.test -size=100M -name=job1 -offset=0MB -bs=4k -name=job2 -offset=10G -bs=512 -output TestResult.log

**FIO命令解析: **
首先我们来看刚才执行的命令: 2个任务并行测试,队列深度64,异步模式,测试数据100M,数据块分别
为4KB和512字节。所以,这个命令是在测试两个线程、队列深度64下的4KB随机写IOPS和512字节随机写
IOPS。所以,从性能调优的角度看,这里测试的是IOPS,不是测带宽。 并且filename=/testfolder
/fio.test, 这代表测试的是文件系统的性能。如果是块设备,则代表测试的是裸设备的性能,例如:
filename=/dev/sdb1
fio -rw=randwrite -ioengine=libaio -direct=1 -thread -numjobs=1 -iodepth=64 -filename=/testfolder/fio.test -size=100M -name=job1 -offset=0MB -bs=4k -name=job2 -offset=10G -bs=512 -output TestResult.log
下面是对刚才执行的命令中,每个参数的介绍
-rw=randwrite:读写模式,randwrite是随机写测试,还有顺序读read,顺序写write,随机读randread,混合读写等。
-ioengine=libaio:libaio指的是异步模式,如果是同步就要用sync。
-direct=1:是否使用directIO。
-thread:使用pthread_create创建线程,另一种是fork创建进程。进程的开销比线程要大,一般都采用thread测试。
–numjobs=1:每个job是1个线程,这里用了几,后面每个用-name指定的任务就开几个线程测试。所以最终线程数=任务数* numjobs。
-iodepth=64:队列深度64.
-filename=/testfolder/fio.test:数据写到/testfolder/fio.test这个文件,也可以是写到一个盘(块设备),例如/dev/sda4
-size=100M:每个线程写入数据量是100M。
-name=job1:一个任务的名字,名字随便起,重复了也没关系。这个例子指定了job1和job2,建立了两个任务。-name之后的就是这个任务独有的参数。
-offset=0MB:从偏移地址0MB开始写。
-bs=4k:每一个BIO命令包含的数据大小是4KB。一般4KB IOPS测试,就是在这里设置。
–output TestResult.log:日志输出到TestResult.log。
**FIO结果解析: **
FIO会为每个Job打印统计信息。 最后面是合计的数值。我们一般看重的是总的性能和延迟。首先看
的是最后总的带宽,bw=827KiB/s (847kB/s), 算成4KB就是212 IOPS。这是一台虚拟机,并且主
机使用的是3Gb的SATA硬盘做RAID1,所以性能很低。
再来看看延迟Latency。Slat是发命令时间,slat (usec): min=4, max=1568, avg=14.11, stdev=10.86说明最短时间4微秒,最长1568微秒,平均14.11微秒,标准差10.86。
clat是命令执行时间。
lat就是总的延迟。
clat percentiles (usec)给出了延迟的统计分布。比如90.00th=[835]说明90%的写命令延迟都在835微秒以内。
其它参数说明
io=执行了多少M的IO
bw=平均IO带宽
iops=IOPS
runt=线程运行时间
bw=带宽
cpu=利用率
IO depths=io队列
IO submit=单个IO提交要提交的IO数
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO完延迟的分布
io=总共执行了多少size的IO
aggrb=group总带宽
minb=最小.平均带宽.
maxb=最大平均带宽.
mint=group中线程的最短运行时间.
maxt=group中线程的最长运行时间.
ios=所有group总共执行的IO数.
merge=总共发生的IO合并数.
ticks=Number of ticks we kept the disk busy.
io_queue=花费在队列上的总共时间.
util=磁盘利用率
[root@RHEL73 fio-master]# cat TestResult.log
job2: (g=0): rw=randwrite, bs=(R) 512B-512B, (W) 512B-512B, (T) 512B-512B, ioengine=libaio, iodepth=64
fio-3.7
Starting 2 threads
job1: (groupid=0, jobs=1): err= 0: pid=20981: Mon Jul 23 23:42:51 2018
write: IOPS=465, BW=1861KiB/s (1906kB/s)(100MiB/55016msec)
slat (usec): min=4, max=1568, avg=14.11, stdev=10.86
clat (usec): min=1912, max=2732.8k, avg=137481.44, stdev=173632.85
lat (usec): min=1942, max=2732.8k, avg=137495.81, stdev=173632.86
clat percentiles (msec):
1.00th=[ 6], 5.00th=[ 9], 10.00th=[ 13], 20.00th=[ 21],
30.00th=[ 33], 40.00th=[ 50], 50.00th=[ 82], 60.00th=[ 132],
70.00th=[ 178], 80.00th=[ 222], 90.00th=[ 300], 95.00th=[ 397],
99.00th=[ 835], 99.50th=[ 1070], 99.90th=[ 1787], 99.95th=[ 2089],
99.99th=[ 2567]
bw ( KiB/s): min= 72, max= 2936, per=100.00%, avg=1873.92, stdev=423.30, samples=109
iops : min= 18, max= 734, avg=468.44, stdev=105.81, samples=109
lat (msec) : 2=0.01%, 4=0.34%, 10=6.68%, 20=12.38%, 50=20.78%
lat (msec) : 100=14.01%, 250=30.48%, 500=12.25%, 750=1.82%, 1000=0.61%
cpu : usr=0.34%, sys=1.17%, ctx=24661, majf=0, minf=9
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.8%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwts: total=0,25600,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
job2: (groupid=0, jobs=1): err= 0: pid=20982: Mon Jul 23 23:42:51 2018
write: IOPS=827, BW=414KiB/s (423kB/s)(100MiB/247637msec)
slat (usec): min=4, max=521, avg=13.35, stdev= 5.26
clat (usec): min=361, max=2211.0k, avg=77369.50, stdev=100484.32
lat (usec): min=375, max=2211.0k, avg=77383.11, stdev=100484.37
clat percentiles (msec):
1.00th=[ 5], 5.00th=[ 8], 10.00th=[ 12], 20.00th=[ 18],
30.00th=[ 25], 40.00th=[ 33], 50.00th=[ 45], 60.00th=[ 60],
70.00th=[ 80], 80.00th=[ 113], 90.00th=[ 182], 95.00th=[ 255],
99.00th=[ 477], 99.50th=[ 609], 99.90th=[ 961], 99.95th=[ 1167],
99.99th=[ 1854]
bw ( KiB/s): min= 99, max= 587, per=49.98%, avg=413.37, stdev=117.31, samples=495
iops : min= 198, max= 1174, avg=826.76, stdev=234.60, samples=495
lat (usec) : 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.02%, 4=0.53%, 10=7.85%, 20=15.80%, 50=29.80%
lat (msec) : 100=22.84%, 250=17.96%, 500=4.32%, 750=0.65%, 1000=0.15%
cpu : usr=0.66%, sys=2.01%, ctx=192728, majf=0, minf=1
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwts: total=0,204800,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
WRITE: bw=827KiB/s (847kB/s), 414KiB/s-1861KiB/s (423kB/s-1906kB/s), io=200MiB (210MB), run=55016-247637msec
Disk stats (read/write):
sda: ios=0/230417, merge=0/1, ticks=0/19323780, in_queue=19323844, util=100.00%
[root@RHEL73 fio-master]#
**FIO配置文件: **
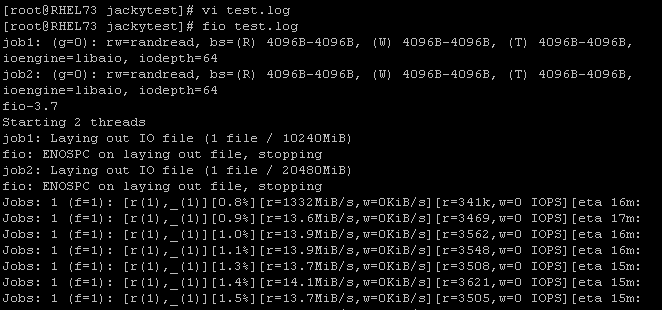
前面的例子都是用命令行来测试,其实也可以用配置文件把这些参数写进去。比如新建FIO配置文件test.log内容如下:
[global]
filename=/dev/sdc
direct=1
iodepth=64
thread
rw=randread
ioengine=libaio
bs=4k
numjobs=1
size=10G
[job1]
name=job1
offset=0
[job2]
name=job2
offset=10G
;–end job file
保存后,只需要fio test.log就能执行测试任务了。

**FIO其它参数: **
FIO是一款功能非常强大的性能测试工具,可以使用“cat README” 和 ”man fio”来查看FIO所有的参数
功能。也可以在以下网址查看关于FIO的详细介绍。
https://linux.die.net/man/1/fio
1,loops=int, 此参数代表测试任务循环执行的次数,如果不带此参数默认为1。这个参数非常有用,
假如我们现在知道测试任务执行一次的时间为1个小时,那么可以通过loops=24来让压力测试跑满24小时
2,lockmem=int,这个参数规定测试占用的内存容量,比如lockmem=1G, 只使用1G内存进行测试,
用此参数可以模拟系统内存很小的测试场景。
3,IO Engine
如下图,FIO中支持多达19种IO Engine,通过这些可以模拟实际应用中大多数IO场景,从而达到最贴近现
实的IO压力测试。在测试时,选择合适的IO Engine可以帮助我们尽可能的模拟出与客户实际应用相同的IO
场景,对售前测试或者售后FA来说都非常有帮助。具体选择哪一种IO Engine需要先了解每个IO Engine的
作用。可以通过上述命令进行学习。

4,混合随机读写
IO的类型取决于客户的应用类型,根据经验,客户的IO类型一般是随机混合IO比较多,比如数据库类应用
都是随机IO,并且是小IO。这种类型的应用如果我们单单只测试顺序读,顺序写,随机读或者随机写,往往
无法真正的反应出真实的IO压力。或者在问题分析时无法真正的找到问题根源。下面举个例子是通过FIO进
行混合随机读写压力测试。
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop
命令说明:
rw=randrw 测试随机写和读的I/O
rwmixread=70 在混合读写的模式下,写占30%
numjobs=30 本次的测试线程为30
runtime=100 测试时间为100秒,如果不写则一直将200G文件分4k每次写完为止。
group_reporting 关于显示结果的,汇总每个进程的信息
ioscheduler=noop Linux IO调度器,Noop调度算法也叫作电梯调度算法,它将IO请求放入到一个FIFO
队列中,然后逐个执行这些IO请求,这个算法在测试SSD的时候并不太合适。
5,通用测试场景
下面是一些通用的测试场景,可以直接运行,或按实际情况适当修改参数后运行
100%随机,100%读, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
100%随机,100%写, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
100%顺序,100%读 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
100%顺序,100%写 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
100%随机,70%读,30%写 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
同时,也可以在FIO测试时使用性能分析监控工具实时查看系统IO。例如在RHEL7中可以使用PCP进行
监测。PCP也是一款非常实用强大的性能分析监控工具。