Gluster是一个分布式扩展文件系统,它允许根据存储消耗需求快速提供额外存储。它将自动故障转移作为
一个主要特性。所有这些都是在没有中央元数据服务器的情况下完成的。适用于媒体流、云存储和CDN(内容
交付网络)等数据密集型工作负载。GlusterFS最初是由Gluster公司开发的,后来被Redhat收购。
常用术语:
Brick: GFS中的存储单元,是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标
识,如’SERVER:EXPORT’
Client: 挂载了GFS卷的设备
DFS: Distributed File System,分布式文件系统,数据被分散到多个存储节点上,并允许客户机通过
网络访问它
Extended Attributes: xattr是一个文件系统的特性,其支持用户或程序关联文件/目录和元数据。
FUSE: Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而
不需要修改内核代码。通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。
GFID: GFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode
glusterd:是一个在可信存储池中的所有服务器上运行的守护进程。
Namespace:每个Gluster卷都导出单个ns作为POSIX的挂载点
Node: 一个拥有若干brick的设备
RDMA: 远程直接内存访问,支持不通过双方的OS进行直接内存访问。
RRDNS: round robin DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法
Self-heal: 用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
Split-brain: 脑裂
Volfile: glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume: 一组bricks的逻辑集合
卷的类型:
卷是一组bricks的逻辑集合,gluster文件系统都是在卷上运行的。Gluster文件系统根据需要支持不同
类型的卷。一些卷可以很好地扩展存储大小,一些卷可以提高性能,还有一些卷可以同时使用
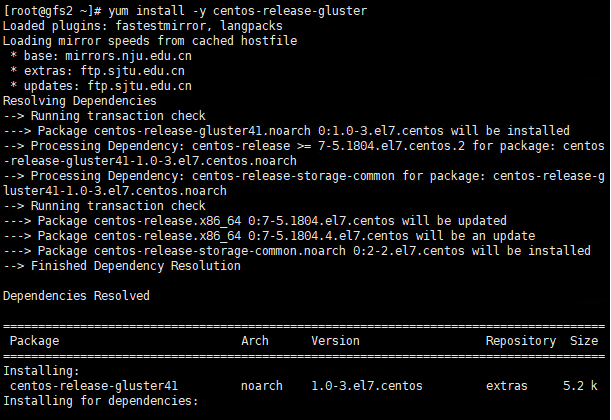
1,分布式卷
分布式卷是默认的Glusterfs卷。在创建卷时,如果没有指定卷的类型,默认选项是创建分布式卷。在分布
式卷中,文件分布在卷中的各个块上。因此,file1只能存储在brick1或brick2中,但不能同时存储在两者
中。因此没有数据冗余。这样一个存储卷的目的是方便和廉价地缩放卷大小。然而,这也意味着一个块故障
将导致完全的数据丢失,并且必须依赖底层硬件来保护数据丢失。
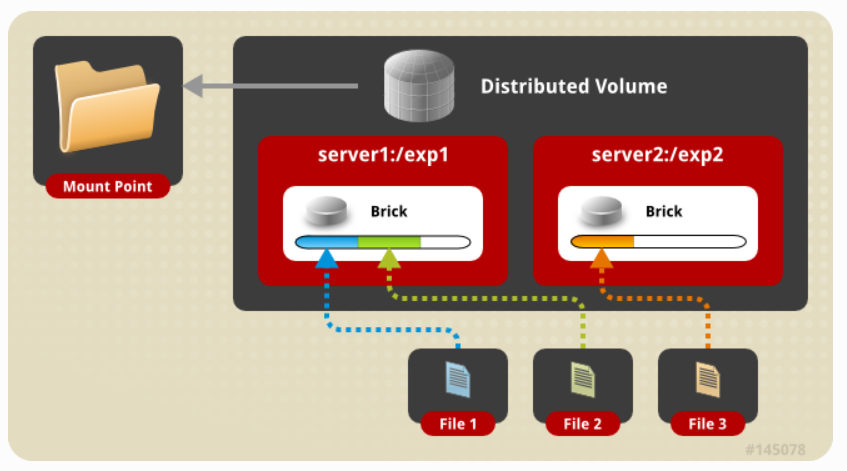
2,复制卷
在复制卷中,我们克服了分布式卷中面临的数据丢失问题。在这里,数据的精确副本保存在所有bricks上。
在创建卷时,客户端可以决定卷中的副本数量。因此,我们需要至少有两个bricks来创建一个包含两个副
本的卷,或者至少有三个砖块来创建一个包含三个副本的卷。这种卷的一个主要优点是,即使一个块出现
故障,数据仍然可以从它的复制块访问。这样的卷用于更好的可靠性和数据冗余。
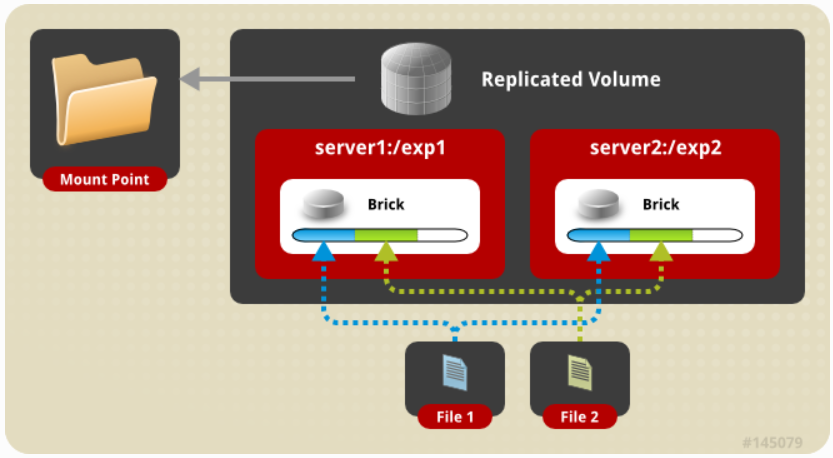
3,分布式复制卷
在这个卷中,文件分布在复制的bricks中。bricks的数量必须是复本数量的倍数。另外,指定bricks的顺
序也很重要,因为相邻的bricks变成了彼此的复制品。当由于冗余和扩展存储而需要高可用性数据时,可以
使用这种卷。如果有8个bricks,复制数是2,那么前两个bricks就变成了彼此的复制品,然后接下来的两
个,以此类推,我们将这个卷称之为4x2卷。类似地,如果有8个砖块,复本数量为4,那么4个bricks就变
成了彼此的复制品,我们将这个卷称之为2x4卷。
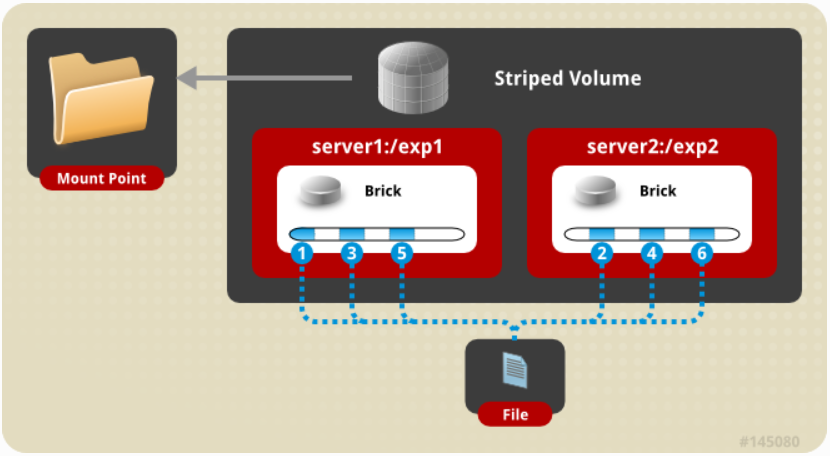
4,条带卷striped glusterfs
如果考虑将一个大文件存储在一个brick中,并且许多客户机同时频繁地访问它。这将对单个brick造成太多
的负载,并会降低性能。在条带卷中,数据被分成不同的条带后存储在brick中。因此,大文件将被分割成更
小的块(等于卷中brick的数量),每个chunk都存储在一个brick中。现在,负载是分布式的,可以更快地获
取文件,但没有提供数据冗余。
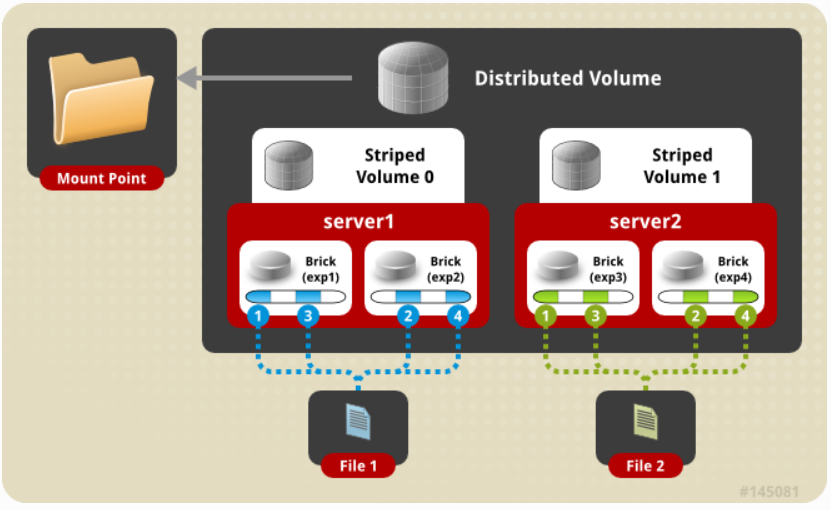
5,分布式的条带卷
与条带卷类似,只是条带现在可以分布在更多的bricks上。但是bricks的数量必须是条带数量的倍数。
因此,如果我们想增加体积大小,我们必须按条带数的倍数添加bricks。
FUSE
GlusterFS是一个用户空间文件系统。这是GlusterFS开发人员最初做出的决定,因为将模块放入linux内核
是一个非常漫长和困难的过程。为了与内核VFS交互,它使用了FUSE(用户空间中的文件系统)。很长一段时间
以来,用户空间文件系统的实现被认为是不可能的。FUSE是为此开发的一种解决方案。FUSE是一个内核模块,
支持内核VFS和非特权用户应用程序之间的交互,它有一个可以从用户空间访问的API。使用这个API,任何类
型的文件系统都可以使用您喜欢的任何语言编写,因为FUSE和其他语言之间有许多绑定。
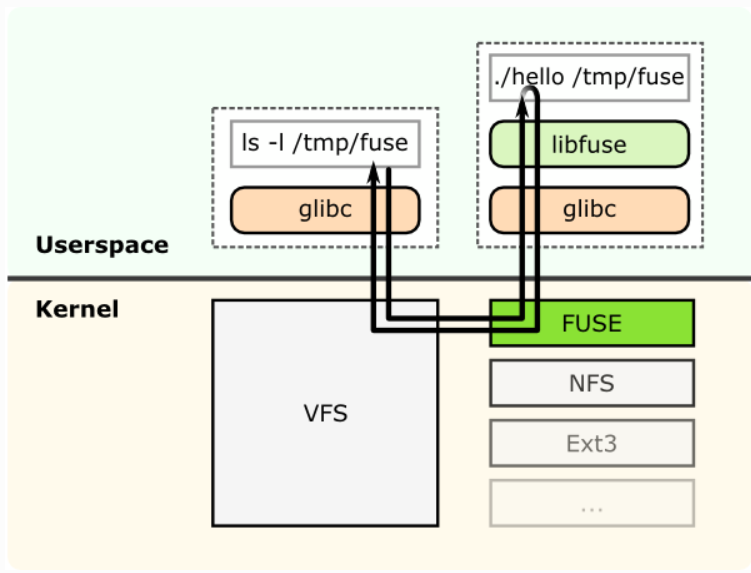
下图显示了一个文件系统“hello world”,它被编译成一个二进制“hello”。它使用文件系统挂载点
/tmp/fuse来执行。然后用户在挂载点/tmp/fuse上发出命令ls -l。这个命令通过glibc到达VFS,
因为挂载/tmp/fuse对应于一个基于fuse的文件系统,所以VFS将它传递给fuse模块。FUSE内核模块
在通过userspace(libfuse)中的glibc和FUSE库后,会与实际的文件系统二进制文件“hello”联系。
结果由“hello”通过相同的路径返回,并到达ls -l命令。
FUSE内核模块与FUSE库(libfuse)之间的通信是通过一个特殊的文件描述符进行的,该描述符是由open
/dev/fuse.得到的这个文件可以被多次打开,获得的文件描述符被传递给挂载syscall,以将描述符与
挂载的文件系统相匹配。
安装环境准备
在本次安装中,我们使用CentOS7 搭建一个复制卷(Replicated Glusterfs Volume)
node
Host Name
IP Address
OS
Disk
node1
gfs1.cluster.local
172.16.80.27
CentOS 7.5
/dev/sda (100GB)
/dev/sdb (100GB)
node2
gfs2.cluster.local
172.16.80.28
CentOS 7.5
/dev/sda (100GB)
/dev/sdb (100GB)
client
gfsc1.cluster.local
172.16.80.29
CentOS 7.5
/dev/sda(40GB)
配置DNS解析
GlusterFS组件使用DNS解析名称,因此需要配置DNS或设置主机条目。如果环境中没有DNS Server,可通过
修改/etc/hosts文件来实现。在所有节点上进行修改。
vi /etc/hosts

配置存储库
在安装GlusterFS之前,我们还需要在两个存储节点上配置GlusterFS存储库
yum install -y centos-release-gluster