
边界网关协议(BGP)是运行于TCP上的一种自治系统的路由协议。 BGP是唯一一个用来处理像因特网
大小的网络的协议,也是唯一能够妥善处理好不相关路由域间的多路连接的协议。BGP构建在EGP的经
验之上。BGP系统的主要功能是和其他的BGP系统交换网络可达信息。网络可达信息包括列出的自治系
统(AS)的信息。这些信息有效地构造了AS互联的拓朴图并由此清除了路由环路,同时在AS级别上可
实施策略决策。目前广泛使用的版本是BGP-4,也就是BGP版本4,BGP-4提供了一套新的机制以支持无
类域间路由。这些机制包括支持网络前缀的通告、取消BGP网络中 “ 类 ” 的概念。BGP-4也引入机制
支持路由聚合,包括AS路径的集合。这些改变为提议的超网方案提供了支持。BGP-4采用了路由向量路
由协议,在配置BGP时,每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“BGP发言人
”。BGP通常应用於比较大型的网络结构中,用作交换不同AS之间的路由资讯,例如ISP与ISP之间的路
由交换。BGP的复杂性在于建立Peers上的一些规限,以及有大量可以影响路由结果的 Attribute,要
学好BGP,必需知道微调这些Attribute的方法。
eBGP与iBGP
与其它路由协议类似,BGP同样需要组成Neighbor来进行运作,在BGP中这个Neighbor关系称为Peer,
Peer之间使用TCP端口179进行沟通。BGP分为Internal BGP(iBGP)和External BGP(eBGP),比如
两个Router在相同的AS之内组成Peer,就会成为iBGP Peer,如果两个组合成Peer的Router属于不同
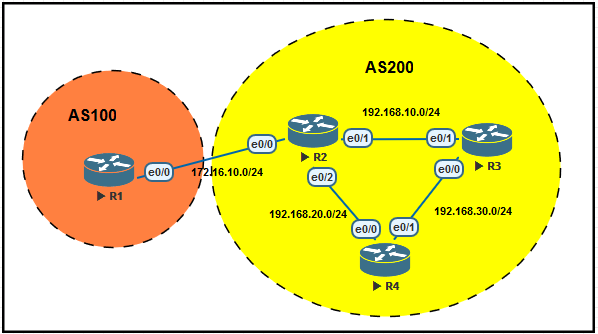
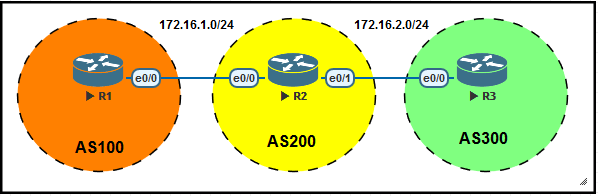
的AS,那么就是eBGP Peer。如下图是一个BGP Peer的示例,R1位于AS100之内,R2和R3位于AS200之
内,R1与R2组成的Peer就属于eBGP Peer, R2与R3组成的Peer就是iBGP Peer。
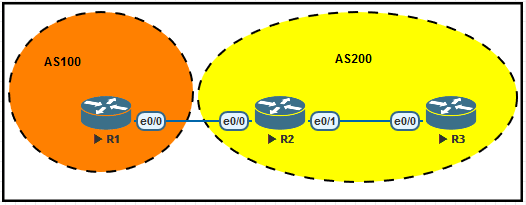
1、我们来简单配置一下这个BGP Peer,首先配置R1,使用如下命令添加接口IP地址,然后配置BGP。
interface e0/0
ip address 172.16.10.1 255.255.255.0
router bgp 100
neighbor 172.16.10.2 remote-as 200
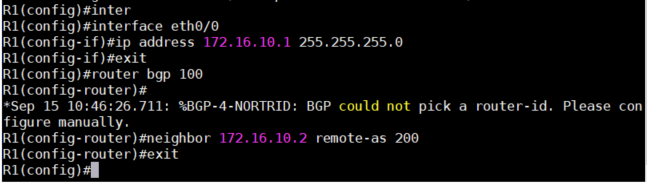
2、配置R2,R2位于R1与R3之间,所以需要配置两条neighbor。
interface e0/0
ip address 172.16.10.2 255.255.255.0
interface e0/1
ip address 10.10.10.2 255.255.255.0
router bgp 200
neighbor 172.16.10.1 remote-as 100
neighbor 10.10.10.3 remote-as 200
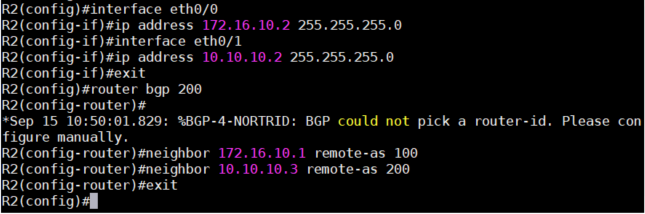
3、同样在R3上进行相应的配置。
interface e0/0
ip address 10.10.10.3 255.255.255.0
router bgp 200
neighbor 10.10.10.2 remote-as 200
4、配置完成,使用如下命令确认Peer是否建立成功。如下图我们在R2上可以看到两条Peer已经建立
成功。
show ip bgp summary

5、在这个Summary信息中,每一项所代表的意思如下:
● Neighbor:Peer Router的IP地址。
● V:BGP的版本。
● AS:Peer Router的AS号,如果这个AS号与上面显示的local AS number相同,就代表是iBGP。否则
就代表是eBGP。
● MsgRcvd&MsgSent:MsgRcvd代表接收到的BGP封包,MsgSent代表传送到Peer的封包,默认情况下
BGP会每分钟传送一次Keepalive msg给Peer,也就是说默认的keepalive time=60秒,所以这两个数
值会不断增加。
● TblVer:传送给这个Peer的最新的BGP Database的版本。
● InQ:显示收到而没有处理的BGP信息,如果这个数值很大,说明有很多信息在排队等待处理,也反
应了CPU很忙,未能及时处理这些包。
● OutQ:表示等待送出的BGP包,如果这个数值很大,说明CPU很忙或者是带宽不够。
● Up/Down:代表Peer之间的连接维持了多久。
● State/PfxRcd:如果显示的是数字,比如0,代表从这个Peer收到的BGP Route的数量,同样也代表
Peer已经成功建立,如果显示的是Active或者Idle,则代表Peer没有建立成功。
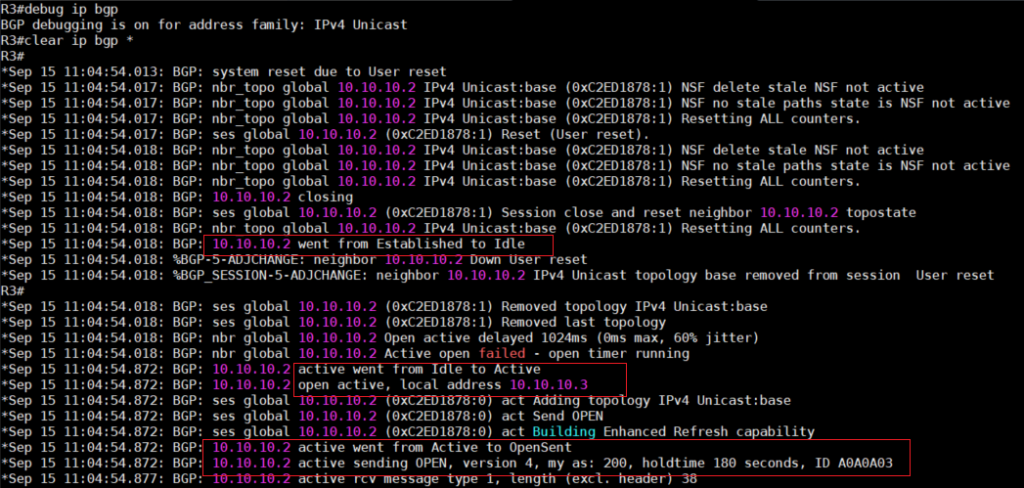
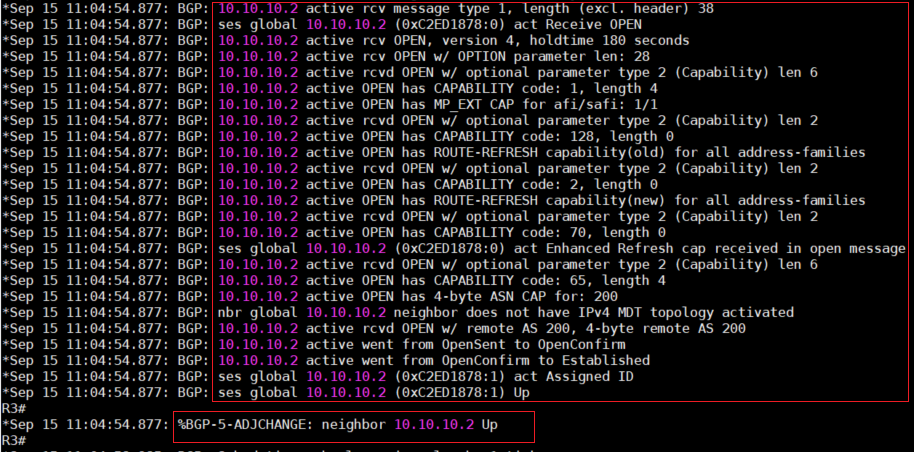
6、使用以下命令可以对Peer的建立过程进行查看或者debug。
debug ip bgp
clear ip bgp *
7、如果配置没有问题,BGP Peer就会进入Estabilished状态,在进入Estabilished状态之前还会经
过几次状态的转换,以下是对这几个状态的介绍:
● IDLE: Router正在寻找Routing Table,找一条能够连接Neighbor的路径。
● Connect:Router已经找到路径,并完成了TCP3次握手。
● OpenSent: 已经传送了BGP的Open封包,告诉对方希望建立Peer。
● OpenConfirm: 收到Neighbor的回复封包,确认可以建立Peer。
● Estabilished:两个Neighbor成功建立Peer。
● Active: 代表Router仍然处于主动传送封包的状态,没有收到对方的回应,如果一直是此状态,代
表Peer建立失败。
Loopback接口的使用
1、在一个AS当中,除了运行BGP之外,通常会运行IGP协议,比如OSPF或EIGRP等等来作路由交换,在
这种情况下,使用Loopback接口作为iBGP的neighbor地址是比较可靠的方式,因为Loopback接口永远
都是UP的,不会down掉。而且Neighbor之间可以通过IGP来寻找到达loopback的路径。相比使用接口
IP地址来当作iBGP的neighbor地址,使用loopback就显得更加灵活,也更加可靠。避免因为接口down
掉而对BGP造成影响。
2、以下图为例,R1在AS100当中,R2、R3和R4在AS200当中,我们假设R2、R3和R4正在运行OSPF路由协
议,如果R2连接到R3的iBGP使用的是R3的e0/1接口IP地址,那么当这个端口出现故障down掉以后,
iBGP就会断开。
3、我们先来简单配置一下R2、R3和R4。
R2:
interface e0/0
ip address 172.16.10.2 255.255.255.0
interface e0/1
ip address 192.168.10.2 255.255.255.0
interface e0/2
ip address 192.168.20.2 255.255.255.0
router ospf 1
network 0.0.0.0 255.255.255.255 area 0
router bgp 200
neighbor 192.168.10.3 remote-as 200
R3:
interface e0/0
ip address 192.168.30.3 255.255.255.0
interface e0/1
ip address 192.168.10.3 255.255.255.0
router ospf 1
network 0.0.0.0 255.255.255.255 area 0
router bgp 200
neighbor 192.168.10.2 remote-as 200
R4:
interface e0/0
ip address 192.168.20.4 255.255.255.0
interface e0/1
ip address 192.168.30.4 255.255.255.0
router ospf 1
network 0.0.0.0 255.255.255.255 area 0
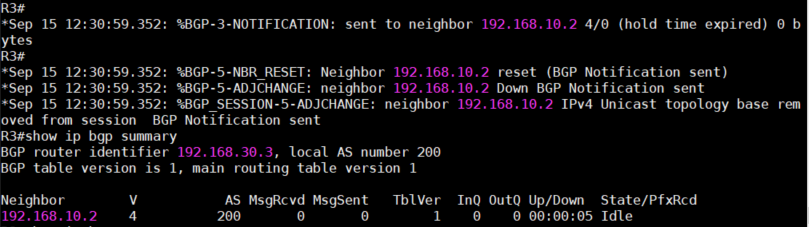
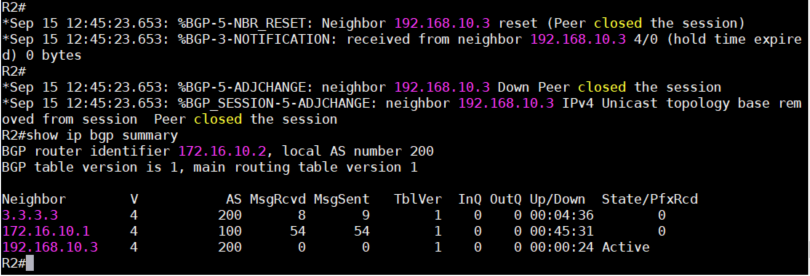
4、配置完成后,iBGP运行正常,此时我们手动shutdown掉R3的e0/1接口,然后等待3分钟,因为BGP的
default hold time是180秒。查看iBGP的连接,状态已经显示为”Idle”。此时如果在R2上查看,状态
应该为”Active”。表明此Peer连接已经断开。
5、现在我们改用loopback接口作为Neighbor的IP地址。设置好loopback 0的IP后,修改BGP配置,将
loopback地址添加到neighbor然后,加入下面这条命令。注意需要在R2和R3都进行操作。
neighbor 3.3.3.3 update-source loopback 0
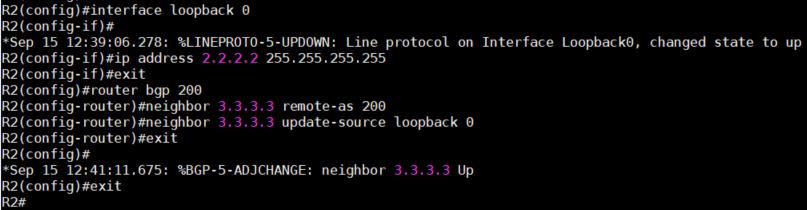
6、此时再次检查iBGP Peer的状态,可以看到Peer已经恢复,并不受前面down掉的接口影响。需要注
意的是,使用Loopback来连接Peer通常只在iBGP上,不要使用Loopback接口来连接eBGP Peer。
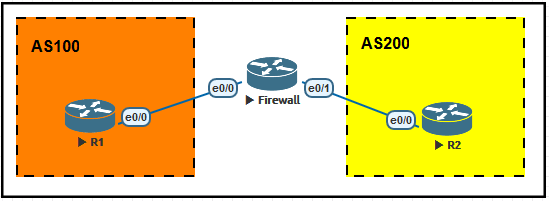
eBGP的Multihop
1、我们知道eBGP连接的Peer位于不同的AS,在现实中两个AS之间很有可能还会有其它设备,比较典型
的例子就是防火墙,因为通常连接其它AS的位置都是网络的边缘,在边缘网络通常会架设有防火墙等
设备以提高安全性。在这种情况下,我们需要使用Multihop来将eBGP Peer连接起来。
2、如下图,假设我们在AS100和AS200之间配置了一台防火墙设备,我们使用一台Router来模拟。
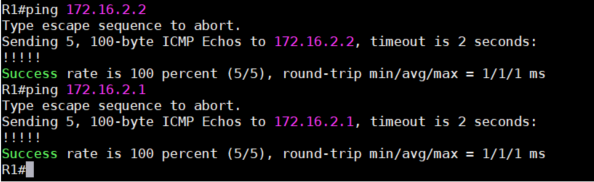
3、基本的配置与前面相同,这里就不重复演示了,主要来看一下按正常方法配置完成后的结果。如下
面的两张图,我们从R1可以正常Ping通R2的地址,但是我们发现BGP Peer并没有建立起来,up/down为
never,说明eBGP Peer一直是没有建立起来的。这是为什么呢?

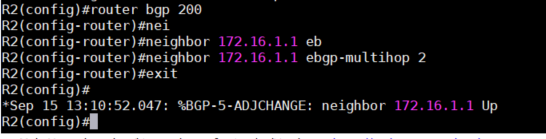
4、这时就需要使用如下命令来告诉eBGP需要多少跳才能找到neighbor。需要在两个Router的BGP配置
里都加入如下命令:
neighbor <ip》 ebgp-multihop
max hop count是两个Router之间相隔的跳数。如下图可以看到,配置完成后,已经提示neighbor状态
变为UP,说明Peer建立成功。

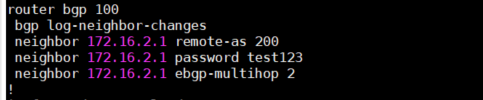
5、为了保证安全性,也可以为BGP Peer设置密码,只要两边设置的密码相同,就可以成为Peer。
通告Network
1、BGP不像OSPF等协议一样,会自动发现路由,BGP不生产路由,只是路由的搬运工,所以在BGP
Peer建立完成以后,并不代表万事大吉了,还需要对Network进行通告,以便在Peer之间交换路由信
息。BGP的network指令与其它协议如OSPF不同,在BGP中,Network指令只会宣告发布一个网段,而不
会加入任何interface接口成为BGP的发布点。因为BGP的neighbor已经让BGP知道了哪些接口已经加入
BGP并且完成了Peer。所以network只发而网段就可以了。另外,如果要让BGP发而一个网段出去,
Router本身的路由表中一定要有该网段的路由信息,否则该网段无法发布。
2、我们以下图为例,R1、R2、R3分别在不同的AS内。我们假设所有基本配置已经完成。
3、我们在R1上配置Loopback 0,然后把这个Loopback网段发布出去。
interface loopback 0
ip address 1.1.1.1 255.255.255.0
router bgp 100
network 1.1.1.0 255.255.255.0

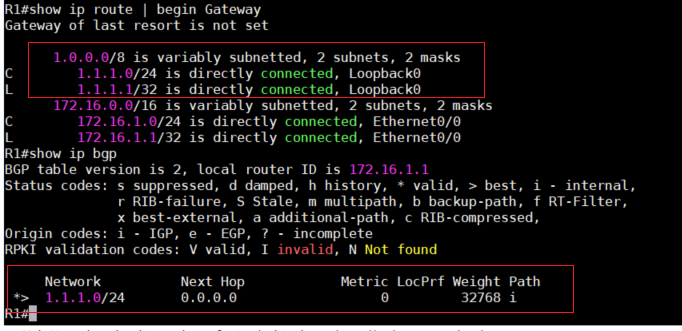
4、先查看一下R1的路由表,确认一下1.1.1.0/24这个网段出现在路由器的路由表中。然后再查看该
网段同样出现在BGP的路由表中。
show ip route
show ip bgp
5、在R2和R3上查看这两个路由表,发现1.1.1.0/24网段也出现在路由器的路由表上和BGP的路由
表上。
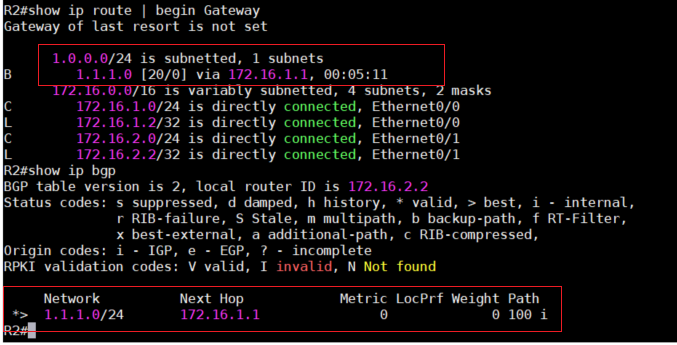
6、如上图,在BGP的路由中,各项所代表的意思如下:
● Network:网段的Network ID及Prefix
● Next Hop:要到达这个网段的下一跳地址,如果显示为0.0.0.0,说明此网段是由本地路由器发布
的。这里的地址必须有路由可达,才会放入路由表中。
● Metric:用来选择最佳路径的一个方法。
● LocPrf:用来选择最佳路径的一个方法。
● Weight:Cisco独有的一个参数,如果这条路由是由本机network指令产生的,就会设定成32768,
它同样也是用来选择最佳路径的一个方法。
● Path:到达这个网段所经过的AS,空的代表该网段是在本机的AS之中
● Origin: 图片中Origin没有显示出来,最后一个”i”其实是Origin的值。Origin同样也是选择最佳
路径的一个方法。Origin有三个值:
● “i”:代表此路由的来源是IGP或者network指令
● “e”:代表此路由的来源是EGP
● “?”:代表此路由是通过redistribute得来的
Next-Hop-self
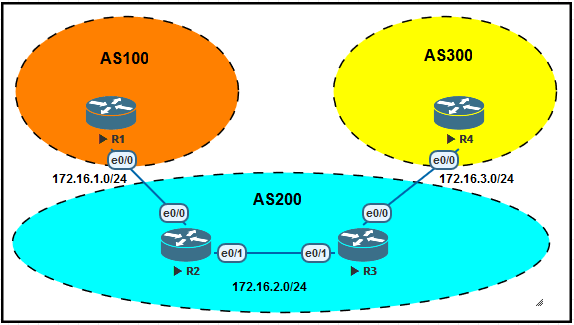
1、前面我们介绍过Next Hop必须是”路由可达”的才能把这条路由加放到路由表。我图们以下图为例,
R1与R2是eBGP,R2与R3是iBGP,R3与R4是eBGP。
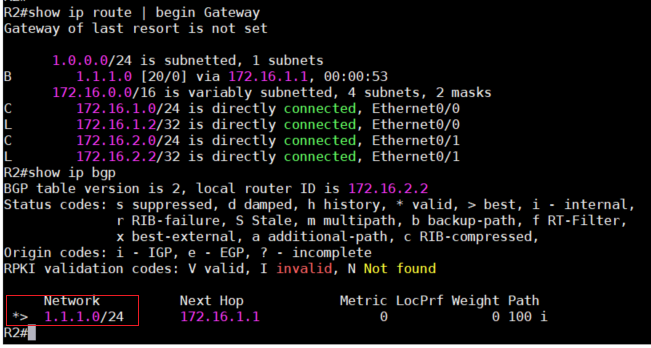
2、假设所有IP及Peer都已经配置完毕,现在我们在R1上配置loopback接口然后将它发布出去,可以
看到R2的BGP database有一个”>”标记,表示BGP选择用Next Hop IP 172.16.1.1来到达1.1.1.1/24
网段。
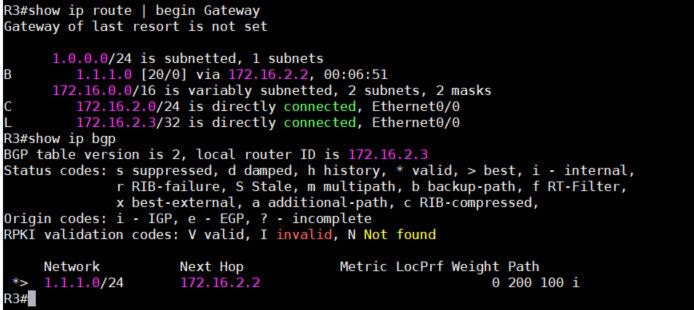
3、再来看一下R3的BGP database,可以看到没有最佳路径,路由表也没有加入1.1.1.0这条路由。
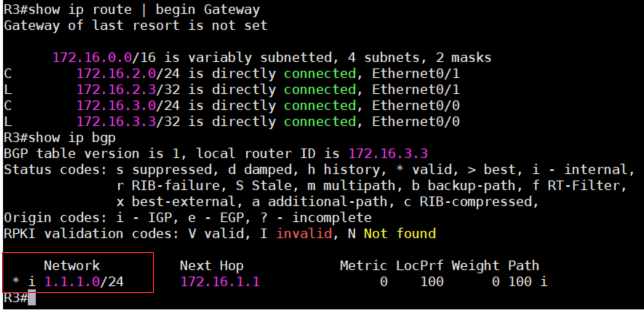
4、对于R3来说,它并没有到达172.16.1.1的路径,所以R3不会把这条路由加入到路由表,至于为什
么下一跳是172.16.1.1而不是172.16.2.2呢,这是因为当BGP把一条路由用iBGP发布给neighbor时,
默认是不会更改其下一跳IP的,这一点很重要,一定要记住了。
5、要解决上面的问题,这里我们可以直接添加一条静态路由,让R3知道怎么去172.16.1.1,然后就
会加入到BGP路由表中。另外一种方法就是使用Next-hop-self命令,迫使R2在发布路由给R3时使用
自己的IP作为下一跳的IP。
neighbor ip next-hop-self

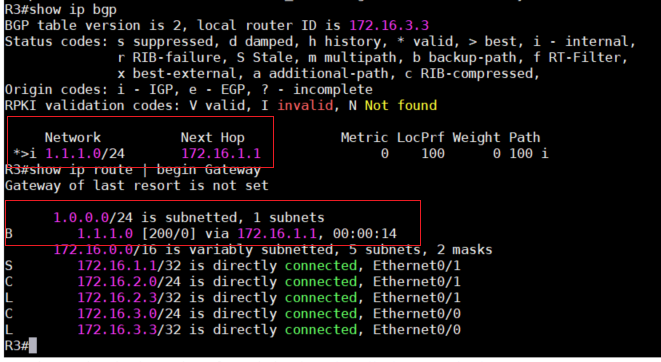
6、再次查看R3的BGP路由表,可以看到有了”>”标记,说明BGP接受了这条最挂路径。同时,路由表中
也加入了这条Route。
Synchronization(同步)
1、在实际的环境中,我们经常需要通过IGP作为中介来让两个或多个iBGP Neighbor连接,如下图的
示例中,AS200当中的R2与R5成为iBGP Peer,然后我们AS100的路由通过AS200发布给AS300。
2、这时我们就需要考虑同步这个问题,当BGP的路由到达R5之后,由于R5开启了IGP,比如OSPF,所以
R5在将路由发布给AS300之前,它会先检查同步条件有没有达成。也就是说从iBGP收回来的路由,必须
也要在路由器的路由表中也能找到。
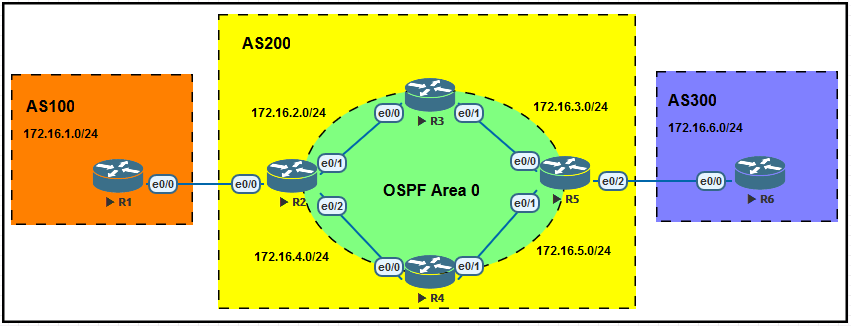
3、在下图中,我们假设所有基本配置已经完成,AS200中的路由器运行OSPF协议的IGP,并都在Area
0中。现在我们在AS100发布1.1.1.0/24到R2,R2收到后发而给R5,R5检查路由表中有没有路由能够去
到1.1.1.0/24网络,如果有,就表示同步了。如果没有,表示不同步。
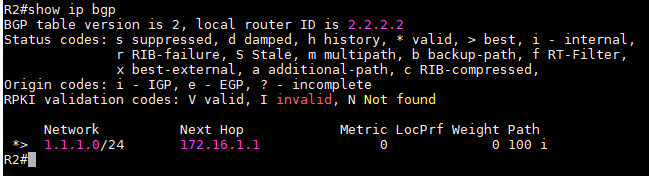
4、在R1发布1.1.1.0/24到R2后,在R2上可以看到这BGP已经接受了这条路由。
5、下面就需要配置同步,有两种方法,第一种是把IGP同步,比如在R2上把BGP路由重新发布到OSPF
之中。
router ospf 1
redistribute bgp 200 subnets
6、另外一种方法就是干脆把同步(Synchronization)关掉,只要在BGP配置中加入”no synchroniza
tion”命令即可,注意需要在R2和R5上都执行此操作。
router bgp 200
no synchronization
7、此时查看R5和R6的路由表和BGP路由表,可以看到R5和R6都收到了BGP Route并且为最挂路径。
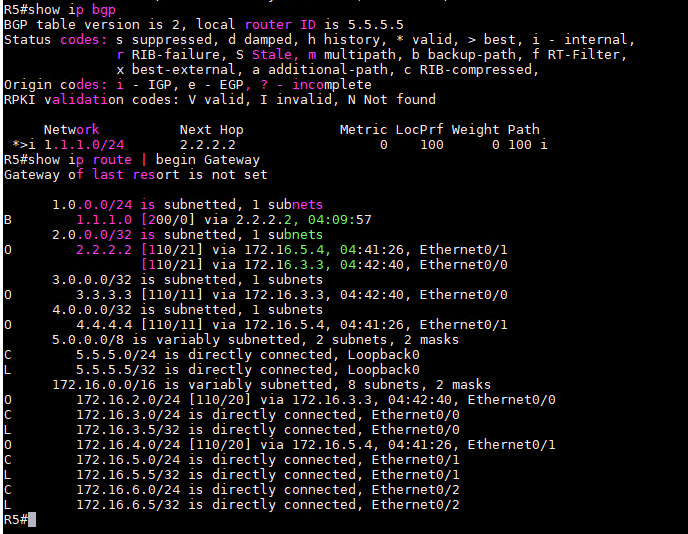
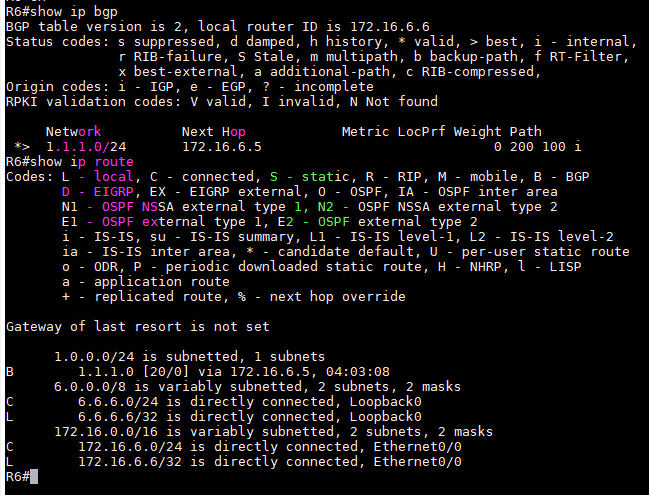
8、如果不使用IGP做为桥梁,将AS内的路由都用iBGP连接起来是否可以?答案是肯定的,但是需要记
住一条重要的规则”从iBGP Peer得到的Route不会发而到另一个iBGP Peer”。在前面的图中,如果
AS200全部使用iBGP,R2从R1收到1.1.1.0/24并发布给R3,但R3不会把它发布给R5,同样R4也不会发
给R5,那么可以在R2与R5也建立iBGP连线来解决。同样为了保证AS里的Router都可以互通,可以把所
有Router都进行联线,但是如果Router数量很多,这显然不是一个好办法,这时可以使用
“neighbor
给另一个iBGP Peer。命令示例如下:
neighbor 172.16.1.1 route-reflector-client
Confederation
1、在比较复杂的网络环境里,比如在一个AS中有很多BGP Router,使用router-reflector来建iBGP
Peer仍然是一个很繁重的工作。这时我们就可以使用Confederation来处理。Confederation可能将一
个AS分割成多个子AS(Sub-AS),只需要每一个子AS里的BGP路由器能到Fully Mesh全网状连接就可
以了,同时对于其它AS的路由器,它们并不会看到这些Sub-AS。
2、以下图为例,我们将图中的AS200分割为两个Sub-AS(10和20),AS100中的R5会和Sub-AS 10中
的R2成为eBGP Peer,AS300中的R6会和Sub-20中的R4成为eBGP Peer。

3、在Sub-AS配置BGP的方法只是多了两条命令,比如R1和R2配置如下
R1:
router bgp 10
bgp confederation identifier 200
bgp confederation peers 20
neighbor 172.16.3.3 remote-as 20
neighbor 172.16.2.2 remote-as 10
R2
router bgp 10
bgp confederation identifier 200
bgp confederation peers 20
neighbor 172.16.2.1 remote-as 10
neighbor 172.16.1.1 remote-as 100



